Hadoop代码分析(一)
本来是要复习考试的,但是看得那个什么编译原理的书就头大。。最近搜了一下hadoop的源码分析,在javaeye上面有一个blog写的不错:http://caibinbupt.iteye.com/blog/262412,毕竟是别人的,自己原来是看过hadoop源码但是没有自己总结过,现在再重新从头整理一下。
hadoop是apache就google提出来的map/reduce分布式计算框架的开源实现,hadoop包括以下子项目:
hdfs:分布式文件系统的具体实现,本来是基于一个名为bigtable的论文而开源实现的;
map/reduce:分布式计算框架;
hbase:一个支持结构化数据或者非结构化或者半结构化的数据的可扩展数据库数据;
zookeeper:用于应用程序中协调个节点配置信息及性能的框架;
等等等等。。。。还有很多具体的介绍就去apache上去看看:http://hadoop.apache.org/
?
当然,接触hadoop的时候大家看得最多的是map/reduce这个基于map/reduce的算法,所以,我也是从这个算法在hadoop中的实现开始了解其机制的,下面是上面那个blog中的一张关于map/reduce的流程图: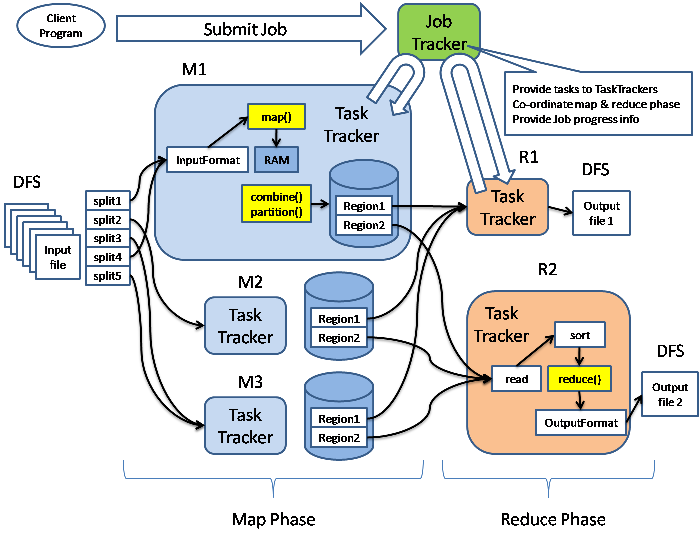
在hadoop的文档中有中文介绍,下面我关于wordcount的例子来解释一下map/reduce,wordcount中的代码分为3部分:map函数,reduce函数和main函数,想要了解hadoop的map/reduce计算机制,我先从main函数中的关于job配置开始(从官网上下载的hadoop包中的文档是0.18的,但是从0.21开始,包的结构就发生了很大改变,我这里就贴0.2+中的代码),wordcount中的main函数如下:
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }?
首先是作业的配置信息:Configuration conf = new Configuration();在之前版本中配置信息都储存在Jobonf类中,而在现在的版本是Configuration中,在eclipse使用前者时会出现以过时警告。看看Configuration中到底有什么吧:
core-default.xml?: Read-only defaults for hadoop.
core-site.xml: Site-specific configuration for a given hadoop installation.
Configutation中主要是提供关于hadoop的一些配置信息,如果没有指明,就从classpath中添加上面两个resource,就是你当初在机器上配置hadoop时所需要修改的fs.default.name等等之类的配置文件,比如文件缓冲块的大小,文件系统的端口号。其次是添加该作业到服务器有关配置,job是描述一个有关map/reduce操作的接口,这个作业是如何被处理的都从这个接口添加到其中,他会指名mapper,reducer,inputformat,outputformat,inputkeyclass等具体的作业信息。
?