Hadoop In Action 第四章(2)
第四章 编写基本的MapReduce程序?
?
4.3 数量统计
?
许多外行人认为统计学就是数量统计,并且许多基本的Hadoop Job就是用于统计数量的。我们已经在第一章中看过统计单词个数的例子了。对于那些专利引用数据,我们可能想要知道专利被引用的次数。这也是一种数量统计。我们期望得到如下形式的结果:
?
1 210000 1100000 11000006 11000007 11000011 11000017 11000026 11000033 21000043 11000044 21000045 11000046 21000049 11000051 11000054 11000065 11000067 3
在每条记录中,专利号与它被引用的次数关联。我们可以编写MapReduce程序来执行这项任务。就像我们之前说的那样,您几乎不会重头编写一个MapReduce程序。您已经有了一个以类似的方式处理数据的MapReduce程序。您需要复制并修改它,直到符合您的要求。
我们之前写过一个以相反的次序显示引用记录的程序。我们可以使程序显示引用次数,而不是引用的专利的列表。我们需要修改Reducer。如果我们选择将引用次数作为IntWritable,我们需要在Reducer代码中的三个地方指定IntWritable。我们在前置注解中将它们称为V3。
public static class Reduce extends MapReduceBase implementsReducer<Text, Text, Text, IntWritable> {public void reduce(Text key, Iterator<Text> values,OutputCollector<Text, IntWritable> output, Reporter reporter)throws IOException {int count = 0;while (values.hasNext()) {values.next();count++;}output.collect(key, new IntWritable(count));}} 通过修改少量的代码行来与类型匹配,我们获得了一个新的MapReduce程序。这个程序看起来只有很小的改动,让我们看看另一个需要更多改动的例子,您会发现它仍然会保留基本的MapReduce程序的结构。
在运行之前的例子之后,我们现在有了统计每个专利被引用的次数的数据。一个有趣的练习是对统计结果进行计数。我们预期大量的专利可能只会被引用一次,而少数的专利将会被引用几百次。观察引用次数的分布是一件有趣的事情。
类型现在是CitationHistogram;所有对MyJob的引用都被更改为对新名称的引用。main()方法几乎永远是一样的。dirver也几乎没有修改。输入和输出的类型仍然分别是KeyValueTextInputFormat和TextOutputFormat。主要的改变是输出键类和输出值类现在是IntWritable,与对应K2和V2的新类型对应。我们也移除了下面的代码行:
job.set("key.value.separator.in.input.line", ",");? 这行代码设置了KeyValueTextInputFormat使用的分隔符,来将每个输入行分解为键/值对。不设置这个属性的话,它的默认值是tab字符,与专利引用数据的格式相符。
这个mapper的数据流与之前的mapper的数据流相似,只是这里我们选择定义并使用一对类变量――citationCount和uno。
public static class MapClass extends MapReduceBase implementsMapper<Text, Text, IntWritable, IntWritable> {private final static IntWritable uno = new IntWritable(1);private IntWritable citationCount = new IntWritable();public void map(Text key, Text value,OutputCollector<IntWritable, IntWritable> output, Reporter reporter)throws IOException {citationCount.set(Integer.parseInt(value.toString()));output.collect(citationCount, uno);}} map()方法增加了一行,用于在设置citationCount时进行类型转换。在类中定义citationCount和uno,而不是在方法中,这纯粹是为了性能。map方法会在有多条记录(为每个JVM进行分隔)时被调用多次。减少在map()中创建的对象的数量可以提升性能并减少垃圾回收。由于我们向output.collect()中传递citationCount和uno,我们需要依赖于output.collect()方法的约定,避免修改那两个对象。(我们会在第5.1.3小节中看到,这种依赖会禁止ChainMapper使用传引用(pass-by-reference)方式)
reducer将每个键的值相加。这看起来性能不好,因为我们知道这些值都是1(准确地说,是uno)。为什么我们需要将计数相加?我们已经考虑了性能。与MapClass不同,Reduce中的output.collect()调用将会实例化一个新的IntWritable,而不是重用已经存在的那个。
output.collect(key, new IntWritable(count));
我们可以通过使用IntWritable类变量来提高性能,但在这个程序中,reduce()被调用的次数要少得多,可能不会超过1000次(在所有的reducer中)。我们不需要对这些特定的代码进行优化。
执行 MapReduce job,并使用引用计数数据,将会显示下列结果。就像我们预期的那样,大量(超过900K)专利只被引用一次,而有些专利被引用了几百次。最热门的专利被引用了779次。
1 9211282 5522463 3803194 2784385 2108146 1631497 1279418 1021559 8212610 66634...411 1605 1613 1631 1633 1654 1658 1678 1716 1779 1
由于这个直方图形式的输出只有几百行代码,我们可以把它放到电子表格中并图形化。图 4.2显示了不同引用频率的专利的数量。这个曲线是按对数趋势变化的。当一个分布显示出对数趋势的曲线时,它就被称为幂率分布(power law distribution)。引用计数直方图看起来是符合这种描述的,尽管它的大致抛物线曲率也暗示着它是一个对数正态分布。
? 就像您在到目前为止看到的那样,MapReduce程序通常不大,并且您可以保持一种特定的结构,以简化部署。大多数的工作是考虑数据流。
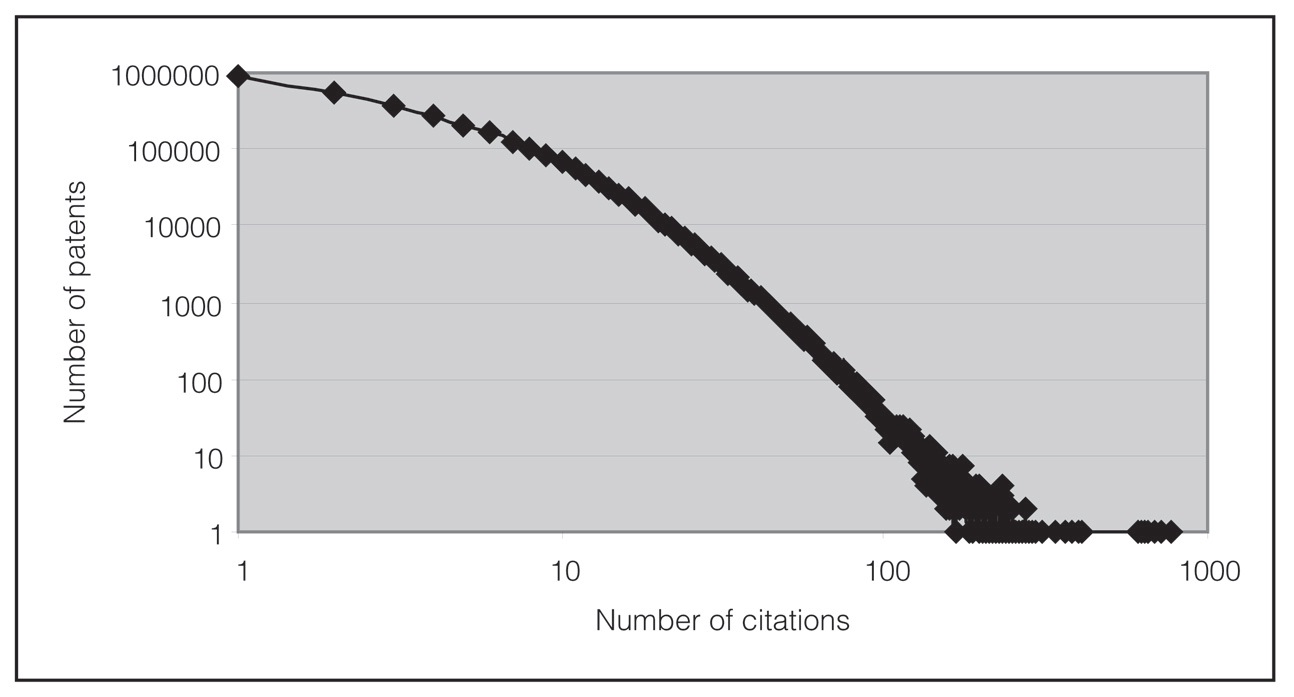
图 4.2 将不同引用频率下的专利的数量图形化。许多专利只被引用一次(或者完全没有,在这张图中没有体现出来)。某些专利被引用了几百次。在对数图上,这看起来与直线十分接近,这被称为幂次分布。
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1246)