Lucene实时索引构建
Lucene可以增量的添加一个段,我们知道,倒排索引是有一定的格式的,而这个格式一旦写入是非常难以改变的,那么如何能够增量建索引呢?Lucene使用段这个概念解决了这个问题,对于每个已经生成的段,其倒排索引结构不会再改变,而增量添加的文档添加到新的段中,段之间在一定的时刻进行合并,从而形成新的倒排索引结构。
然而也正因为Lucene的事务性,使得Lucene的索引不够实时,如果想Lucene实时,则必须新添加的文档后IndexWriter需要commit,在搜索的时候IndexReader需要重新的打开,然而当索引在硬盘上的时候,尤其是索引非常大的时候,IndexWriter的commit操作和IndexReader的open操作都是非常慢的,根本达不到实时性的需要。
好在Lucene提供了RAMDirectory,也即内存中的索引,能够很快的commit和open,然而又存在如果索引很大,内存中不能够放下的问题。
所以要构建实时的索引,就需要内存中的索引RAMDirectory和硬盘上的索引FSDirectory相互配合来解决问题。
1、初始化阶段
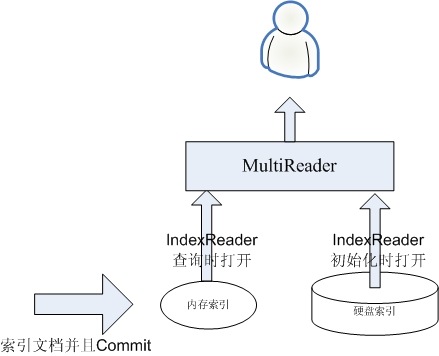
首先假设我们硬盘上已经有一个索引FileSystemIndex,由于IndexReader打开此索引非常的慢,因而其是需要事先打开的,并且不会时常的重新打开。
我们在内存中有一个索引MemoryIndex,新来的文档全部索引到内存索引中,并且是索引完IndexWriter就commit,IndexReader就重新打开,这两个操作时非常快的。
如下图,则此时新索引的文档全部能被用户看到,达到实时的目的。
然而经过一段时间,内存中的索引会比较大了,如果不合并到硬盘上,则可能造成内存不够用,则需要进行合并的过程。
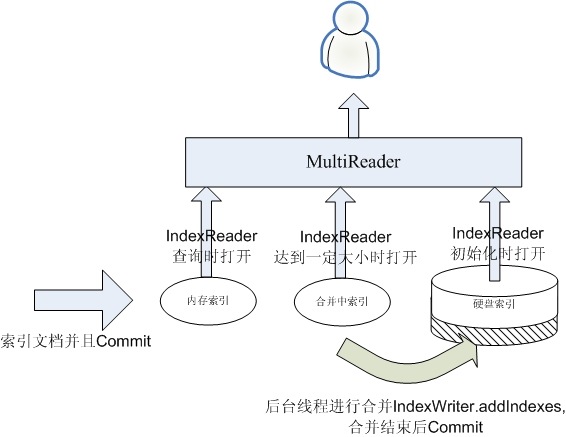
当然在合并的过程中,我们依然想让我们的搜索是实时的,这是就需要一个过渡的索引,我们称为MergingIndex。
一旦内存索引达到一定的程度,则我们重新建立一个空的内存索引,用于合并阶段索引新的文档,然后将原来的内存索引称为合并中索引,并启动一个后台线程进行合并的操作。
在合并的过程中,如果有查询过来,则需要三个IndexReader,一个是内存索引的IndexReader打开,这个过程是很快的,一个是合并中索引的IndexReader打开,这个过程也是很快的,一个是已经打开的硬盘索引的IndexReader,无需重新打开。这三个IndexReader可以覆盖所有的文档,唯一有可能重复的是,硬盘索引中已经有一些从合并中索引合并过去的文档了,然而不用担心,根据Lucene的事务性,在硬盘索引的IndexReader没有重新打开的情况下,背后的合并操作它是看不到的,因而这三个IndexReader所看到的文档应该是既不少也不多。合并使用IndexWriter(硬盘索引).addIndexes(IndexReader(合并中索引)),合并结束后Commit。
如下图:
?
3、重新打开硬盘索引的IndexReader当合并结束后,是应该重新打开硬盘索引的时候了,然而这是一个可能比较慢的过程,在此过程中,我们仍然想保持实时性,因而在此过程中,合并中的索引不能丢弃,硬盘索引的IndexReader也不要动,而是为硬盘索引打开一个临时的IndexReader,在打开的过程中,如果有搜索进来,返回的仍然是上述的三个IndexReader,仍能够不多不少的看到所有的文档,而将要打开的临时的IndexReader将能看到合并中索引和原来的硬盘索引所有的文档,此IndexReader并不返回给客户。如下图:
?
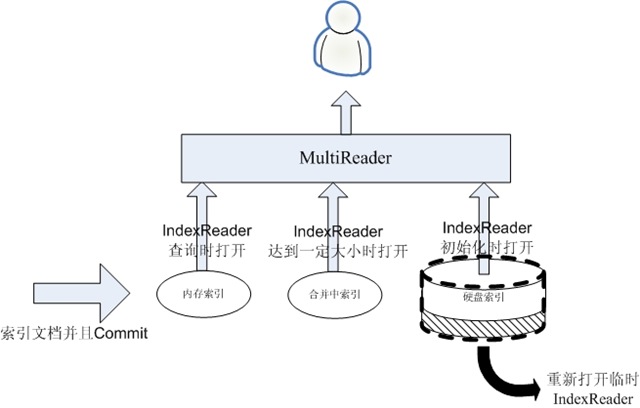
当临时的IndexReader被打开的时候,其看到的是合并中索引的IndexReader和硬盘索引原来的IndexReader之和,下面要做的是:
(1) 关闭合并中索引的IndexReader
(2) 抛弃合并中索引
(3) 用临时的IndexReader替换硬盘索引原来的IndexReader
(4) 关闭硬盘索引原来的IndexReader。
上面说的这几个操作必须是原子性的,如果做了(2)但没有做(3),如果来一个搜索,则将少看到一部分数据,如果做了(3)没有做(2)则,多看到一部分数据。
所以在进行上述四步操作的时候,需要加一个锁,如果这个时候有搜索进来的时候,或者在完全没有做的时候得到所有的IndexReader,或者在完全做好的时候得到所有的IndexReader,这时此搜索可能被block,但是没有关系,这四步是非常快的,丝毫不影响替代性。
如下图:
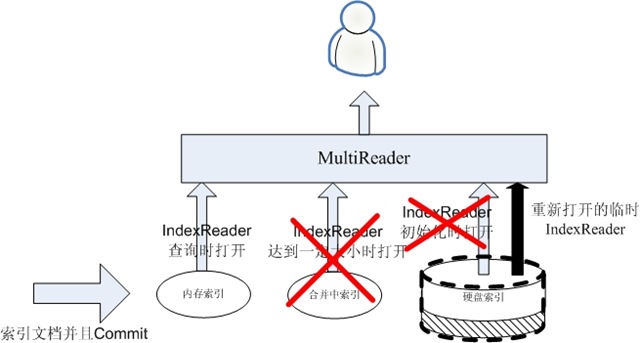
经过这几个过程,又达到了第一步的状态,则进行下一个合并的过程。
5、多个索引有一点需要注意的是,在上述的合并过程中,新添加的文档是始终添加到内存索引中的,如果存在如下的情况,索引速度实在太快,在合并过程没有完成的时候,内存索引又满了,或者硬盘上的索引实在太大,合并和重新打开要花费太长的时间,使得内存索引以及满的情况下,还没有合并完成。
为了处理这种情况,我们可以拥有多个合并中的索引,多个硬盘上的索引,如下图:
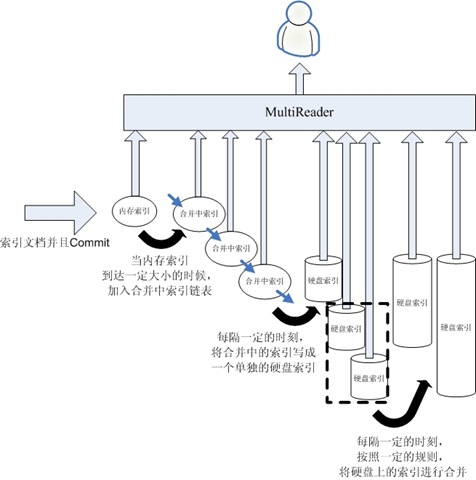
?
新添加的文档永远是进入内存索引 当内存索引到达一定的大小的时候,将其加入合并中索引链表 有一个后台线程,每隔一定的时刻,将合并中索引写入一个新的硬盘索引中取。这样可以避免由于硬盘索引过大而合并较慢的情况。硬盘索引的IndexReader也是写完并重新打开后才替换合并中索引的IndexReader,新的硬盘索引也可保证打开的过程不会花费太长时间。 这样会造成硬盘索引很多,所以,每隔一定的时刻,将硬盘索引合并成一个大的索引。也是合并完成后方才替换IndexReader大家可能会发现,此合并的过程和Lucene的段的合并很相似。然而Lucene的一个函数IndexReader.reopen一直是没有实现的,也即我们不能选择哪个段是在内存中的,可以被打开,哪些是硬盘中的,需要在后台打开然后进行替换,而IndexReader.open是会打开所有的内存中的和硬盘上的索引,因而会很慢,从而降低了实时性。
1 楼 yangfuchao418 2010-11-08 删除我的评论? 2 楼 yuhe 2010-11-08 呵呵,不错。 3 楼 shunai 2010-11-08 学习学习!! 4 楼 forfuture1978 2010-11-09 欢迎访问原文章地址: