KMeansәНKMedoid өДMatlabКөПЦ
KMeansәНKMedoidЛг·ЁКЗҫЫАаЛг·ЁЦРұИҪПЖХұйөД·Ҫ·ЁЈ¬ұҫОДҪІБЛЖдФӯАнәНmatlabЦРКөПЦөДҙъВлЎЈ
1.ДҝұкЈә
ХТіцТ»ёц·ЦёоЈ¬К№өГҫаАлЖҪ·ҪәНЧоРЎ
2.K-MeansЛг·ЁЈә
1. Ҫ«КэҫЭ·ЦОӘkёц·ЗҝХЧУјҜ
2. јЖЛгГҝёцАаЦРРДөгЈЁk-meansЦРУГЛщУРөгөДЖҪҫщЦөЈ¬K-medoidУГАлёГЖҪҫщЦөЧоҪьөДТ»ёцөгЈ©center
3. Ҫ«ГҝёцobjectҫЫАаөҪЧоҪьөДcenter
4. ·ө»Ш2Ј¬өұҫЫАаҪб№ыІ»ФЩұд»ҜөДКұәтstop
ёҙФУ¶ИЈә
OЈЁkndtЈ©
-јЖЛгБҪөгјдҫаАлЈәd
-Цё¶ЁАаЈәO(kn) ,kКЗАаКэ
-өьҙъҙОКэЙППЮЈәt
3.K-MedoidsЛг·Ё:
1. Лж»ъСЎФсkёцөгЧчОӘіхКјmedoid
2.Ҫ«ГҝёцobjectҫЫАаөҪЧоҪьөДmedoid
3. ёьРВГҝёцАаөДmedoidЈ¬јЖЛгobjective function
4. СЎФсЧојСІОКэ
4. ·ө»Ш2Ј¬өұёчАаmedoidІ»ФЩұд»ҜөДКұәтstop
ёҙФУ¶ИЈә
OЈЁ(n^2)dЈ©
-јЖЛгёчөгјдБҪБҪҫаАлOЈЁ(n^2)dЈ©
-Цё¶ЁАаЈәO(kn) ,kКЗАаКэ
4.МШөгЈә
-ҫЫАаҪб№ыУліхКјөгУР№ШЈЁТтОӘКЗЧцsteepest descent from a random initial starting ointЈ©
-КЗҫЦІҝЧоУЕҪв
-ФЪКөјКЧцөДКұәтЈ¬Лж»ъСЎФс¶аЧйіхКјөгЈ¬ЧоәуСЎФсУөУРЧоөНTSDЈЁTotoal Squared DistanceЈ©өДДЗЧй
===================
ПВГжКЗОТУГmatlabЙПөДКөПЦЈә
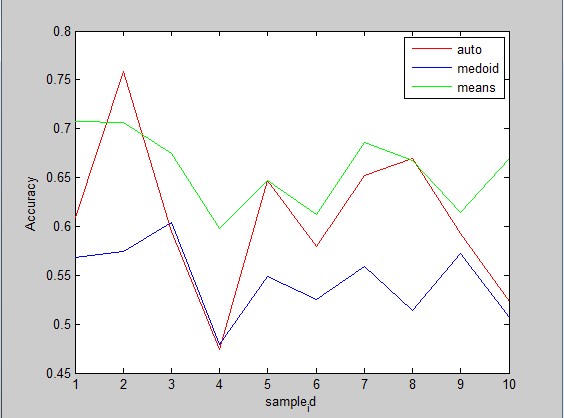
ЛөГчЈәfeaОӘСөБ·СщұҫКэҫЭЈ¬gndОӘСщұҫұкәЕЎЈЛг·ЁЦРөДЛјПләНЙПГжРҙөДТ»ДЈТ»СщЈ¬ФЪЧоәуөДЕР¶Пaccuracy·ҪГжЈ¬УЙУЪҫЫАаәН·ЦАаІ»Н¬Ј¬Ц»КЗөГөҪТ»Р© cluster Ј¬¶шІўІ»ЦӘөАХвР© cluster УҰёГұ»ҙтЙПКІГҙұкЗ©Ј¬»тХЯЛөЎЈУЙУЪОТГЗөДДҝөДКЗәвБҝҫЫАаЛг·ЁөД performance Ј¬ТтҙЛЦұҪУјЩ¶ЁХвТ»ІҪДЬКөПЦЧоУЕөД¶ФУҰ№ШПөЈ¬Ҫ«Гҝёц cluster ¶ФУҰөҪТ»АаЙПИҘЎЈТ»ЦЦ°м·ЁКЗГ¶ҫЩЛщУРҝЙДЬөДЗйҝцІўСЎіцЧоУЕҪвЈ¬БнНвЈ¬¶ФУЪХвСщөДОКМвЈ¬ОТГЗ»№ҝЙТФУГ Hungarian algorithm АҙЗуҪвЎЈҫЯМеөДHungarianҙъВлОТ·ЕФЪБЛЧКФҙАпЈ¬өчУГ·Ҫ·ЁТСҫӯРҙФЪПВГжәҜКэЦРБЛЎЈПВГжёшіцKmeans&KmedoidЦчәҜКэЎЈ
Kmeans.m әҜКэЈә
7АаҫЫАаЈә
№ШУЪMachine Learningёь¶аөДС§П°ЧКБПУлПа№ШМЦВЫҪ«јМРшёьРВЈ¬ҫҙЗл№ШЧўұҫІ©ҝНәНРВАЛОўІ©Sophia_qingЎЈ