数据结构与算法学习六:堆排序
一.?定义?
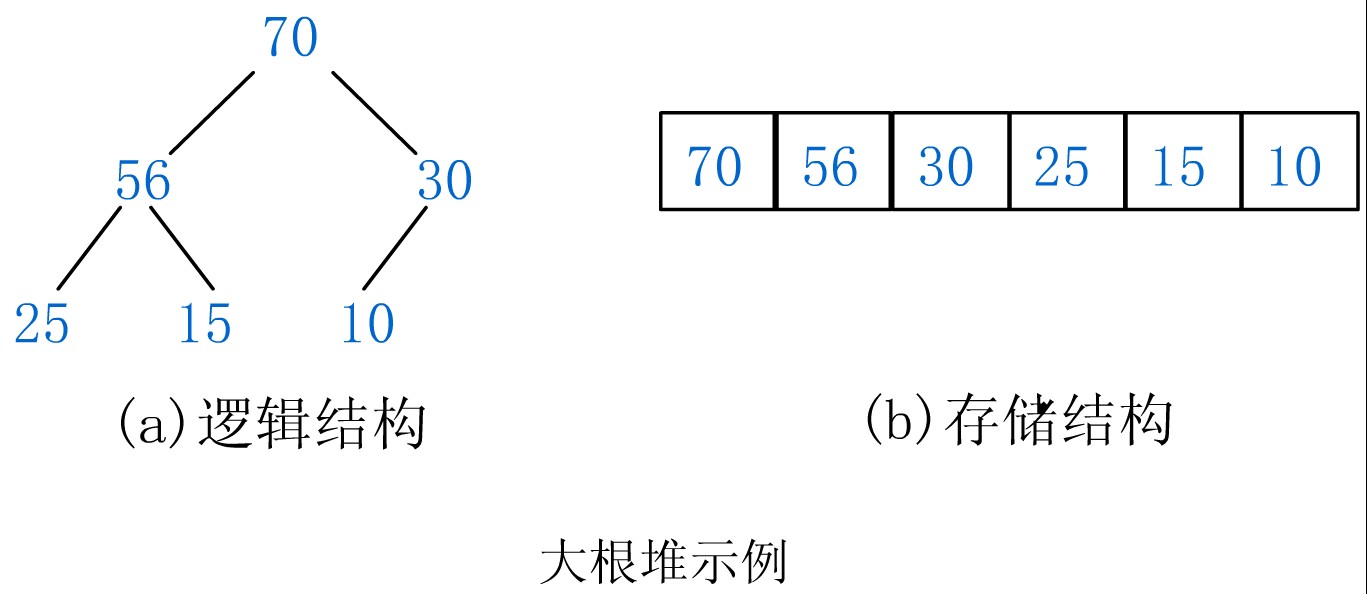
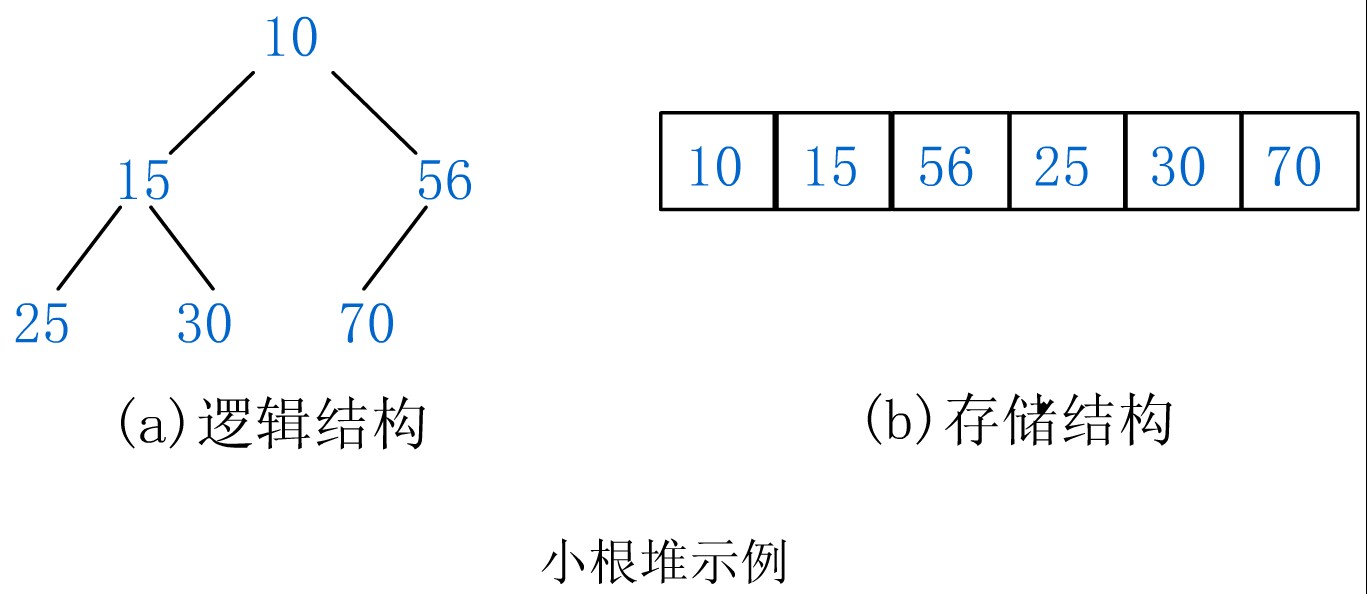
?
?
二. 排序方法(以大根堆为例)
三. 动画演示
???? http://student.zjzk.cn/course_ware/data_structure/web/flashhtml/duipaixu.htm
?
四. Java代码
?
private static int parentIdx(int childIdx) { return (childIdx - 1) / 2; //索引从0开始, 注意childIdx=0时返回0 } private static int leftChildIdx(int parentIdx) { return parentIdx*2 + 1; } /** * 构建大顶堆. */ private static void buildMaxHeap(int[] datas) { int lastIdx = datas.length -1; for(int i=parentIdx(lastIdx); i>=0; i--) { //几个父节点 int k = i; //当前父节点k=i while(leftChildIdx(k) <= lastIdx) { int j = leftChildIdx(k); if(j < lastIdx) { //有两个孩子 if(datas[j] <= datas[j+1]) { //右孩子比较大, 选择大的 j++; } } if(datas[k] >= datas[j]) { //父的比较大 break; } else { SortUtil.swap(datas, k, j); k = j; //父节点重新赋值为原父节点的左孩子节点或者右孩子节点 } } } } /** * 堆顶改变, 要维护大顶堆. */ private static void maintainMaxHeap(int[] datas, int lastIdx) { int k = 0; while(k <= parentIdx(lastIdx)) { int j = leftChildIdx(k); if(j < lastIdx) { //有两个孩子 if(datas[j] <= datas[j+1]) { //j+1 比较大, 选择大的 j++; } } if(datas[k] < datas[j]) { //父结点比较小 SortUtil.swap(datas, k, j); k = j; } else { break; } } } public static int[] sort(int[] datas) { buildMaxHeap(datas); int lastIdx = datas.length - 1; while(lastIdx > 0) { SortUtil.swap(datas, 0, lastIdx); lastIdx--; if(lastIdx > 0) { maintainMaxHeap(datas, lastIdx); } } return datas; } ?
?
五.时间复杂度和稳定性
?
六.堆排序和直接插入排序
???? 直接选择排序中,为了从data[0..n]中选出关键字最小的记录,必须进行n-1次比较,然后在data[2..n]中选出关键字最小的记录,又需要做n-2次比较。事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
??? 堆排序可通过树形结构保存部分比较结果,可减少比较次数。
?