JAVA网络爬虫的实现
记得在刚找工作时,隔壁的一位同学在面试时豪言壮语曾实现过网络爬虫,当时的景仰之情犹如滔滔江水连绵不绝。后来,在做图片搜索时,需要大量的测试图片,因此萌生了从Amazon中爬取图书封面图片的想法,从网上也吸取了一些前人的经验,实现了一个简单但足够用的爬虫系统。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成,其基本架构如下图所示: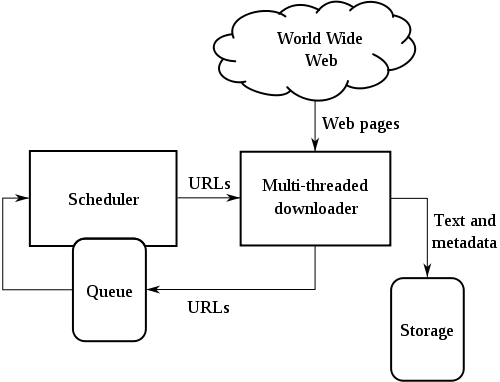
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。对于垂直搜索来说,聚焦爬虫,即有针对性地爬取特定主题网页的爬虫,更为适合。
本文爬虫程序的核心代码如下:
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
更多的关于robot.txt的具体写法,可参考以下这篇文章:
http://www.bloghuman.com/post/67/
getContent内部使用apache的httpclient 4.1获取网页内容,具体代码如下:
如此,便构建了一个简单的网络爬虫程序,可以使用以下程序来测试它:
当然,你可以为它赋予更为高级的功能,比如多线程、更智能的聚焦、结合Lucene建立索引等等。更为复杂的情况,可以考虑使用一些开源的蜘蛛程序,比如Nutch或是Heritrix等等,就不在本文的讨论范围了。