Digester 1.0 源码阅读近来在学习tomcat的源码,里面有一部分是使用Digester来解析xml文件的过程。感觉这个
Digester 1.0 源码阅读
近来在学习tomcat的源码,里面有一部分是使用Digester来解析xml文件的过程。感觉这个工具的代码量比较小,就稍微研究了一下,我近来发现研究开源的代码要从最小版本开始研究,这样
研究有下面一些好处(个人感觉):
1. 一般来说代码量比较小,阅读起来稍微简单一些;
2. 容易和作者产生共鸣;
3. 一般来说都是基于第一版本向上重构,可以进一步和作者进行共鸣。
有一篇博客我详细介绍了Digester的使用,大家可以参考我的另一篇博客。
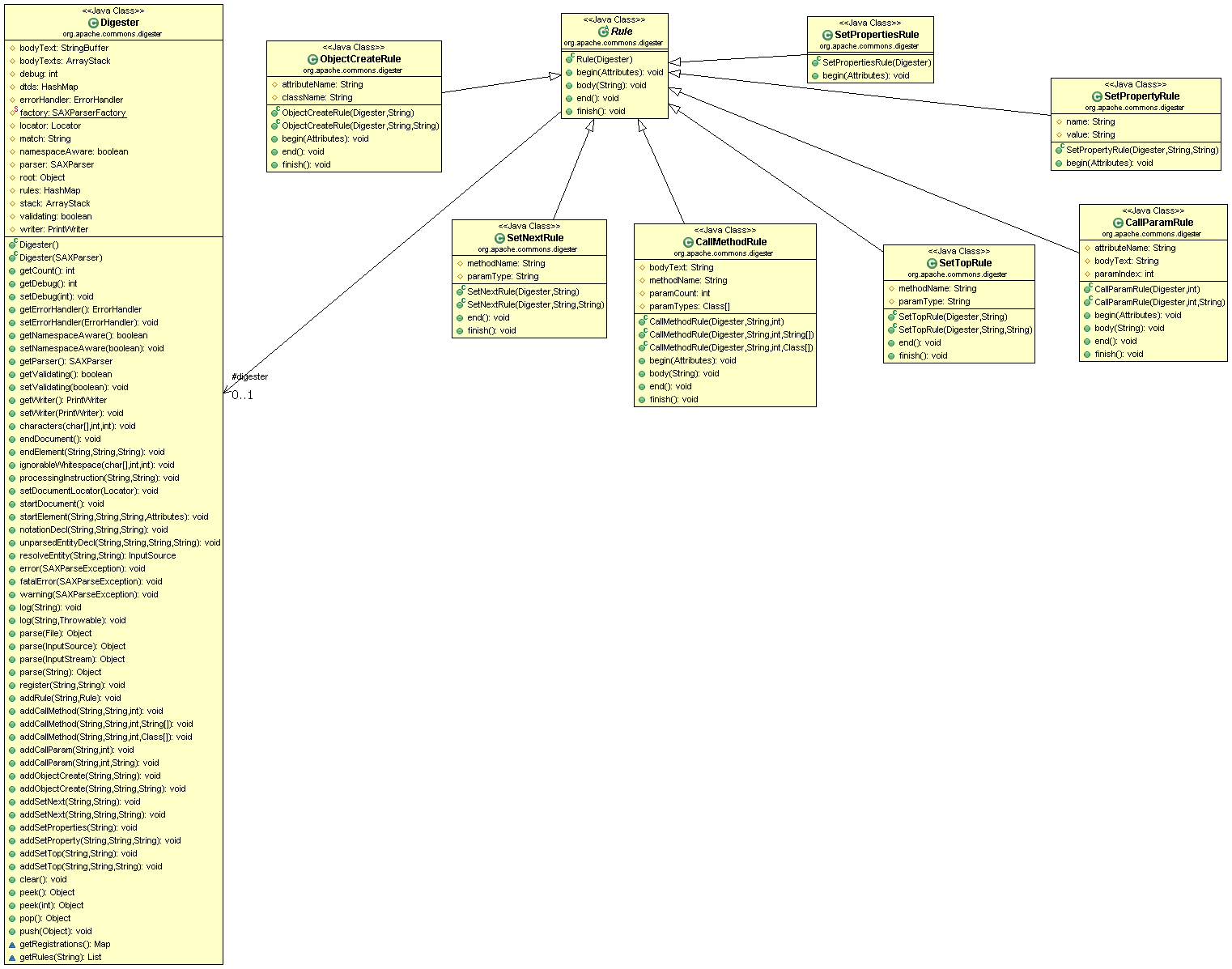
大家可以看一下类结构图:
1. 首先Digester类是一个核心,它实现了XML解析的所有逻辑,重点有两个全局
变量,一个是ArrayStack bodyTexts,这个里面保存着任何两个节点之间的内容,
我也不知道这样描述合适不,稍微讲一下吧。
<students><student><name value="Test Person" /></student> </students>
遇到students节点后,会将“”压到栈中,遇到student节点后,会将\n\t压入到栈中,遇到
name节点后会将\n\t\t压入到栈中,我想大家就明白了,就是把所有的内容都会压入到栈中。
还有一个全局变量是ArrayStack stack,这个里面保存着压入到栈中的对象,比如一般我们会
将root对象压入到栈中,然后遇到student节点后会创建一个对象并把它压入到栈中。
2. 在Digester的startElement方法会触发当前所有匹配的rule的begin方法。
在endElement方法里面会触发当前所有匹配的rule的body方法,接着会触发所有匹配rule的
end方法, 在endDocument方法里面会触发当前所有匹配rule的finish方法,来完成一下善后处理。
3. 其实bodyTexts的变化主要是在startElement和endElement方法进行的,而stack的变化则是
主要在我们定义的一些rule里面操作的,比如ObjectCreateRule,就是创建一个新的对象,然后
将它压入到栈中。
4. 我们来简单的讲一下rule的实现吧,Rule抽象类主要是定义了一些操作,我们也讲过了主要是在
startElement和endElement方法以及endDocument方法里面触发。
5. ObjectCreateRule就是在begin方法里面创建一个对象,并把它压入到栈中,而目标类我们可以
定义在xml的属性中的,这一点我们不惊奇,因为Digester的初衷就是为了解析struts1的配置文件的。
在end方法里面把当前对象从栈中弹出。
6. SetNextRule和SetTopRule和相似,我到理解就是一个是setChild一个是setParent,就是基于栈中
的两个元素来进行操作的。 在SetNextRule里面,child是栈顶元素,parent是栈中的第二个元素。在
SetTopRule中,parent是栈顶元素,child是栈中的第二个元素。
7. SetProperitesRule很好理解就是用反射去给元素设置上相应的值, SetPropertyRule很不好理解,不过
看了例子之后应该也没有问题,就是真正的name和value是用另外的属性来保存的。
8. CallMethodRule和CallParamRule是配合使用的,在CallMethodRule里面定义了要调用的函数的名称,参数个数,参数类型等信息,如果参数个数为0,则是使用当前的节点里面的内容作为参数,如果参数的类型信息没有传递,则是使用的是String类型。 然后将函数的参数信息构造成一个String类型的数组,等待CallParamRule来进行赋值。 CallParamRule则是定义了要赋值的参数index和相应的值,这两个配合的很好,感觉设计的很巧妙。
9. 还有Digeister的rules是一个Map<String,ArrayList<Rule>>类型的一个数据结构, 所以它的顺序是
put和get的顺序是相同的。
读源码后的感受:
虽然使用了ArrayStack bodyTexts来保存节点的content信息,但是保存的是一个StirngBuffer bodyText对象,而清空它使用的是bodyText.setLength(0),所以栈中的内容每时每刻都是相同的,感觉这个栈没有发挥它的最大 作用,这个不明白为什么?????
现在Digester的最新源码是2.0,中间有1.4 1.8 和 2.0, 我都会去阅读的,并分享给大家。 还希望高手能解决我的疑问。