通过ibatis实现轻量级的水平切分(已更新,ibatis原生api也可以实现sharding)
最近想在自己的项目里实现DB sharding功能,正好前段时间研究过ibatis的源码于是就在ibatis的基础上进行了一些修改。另一方面也是为了练练手。这个sharding的实现主要是基于我项目中的需求实现的可能有很多考虑不周的地方,希望各位大牛拍砖。如果有人感兴趣愿意一起来发展这个项目,本人也非常欢迎各位的加入。
Shardbatis是在mybatis 2.3.5代码的基础上进行一些扩展实现数据水平切分功能。 数据的水平切分包括多数据库的切分和多表的数据切分。目前shardbatis已经实现了单数据库的数据多表水平切分
mybatis2.3.5的核心类图(包含了spring对ibatis的封装SqlMapClientTemplate)如下(其他版本的ibatis的类图有略微不同)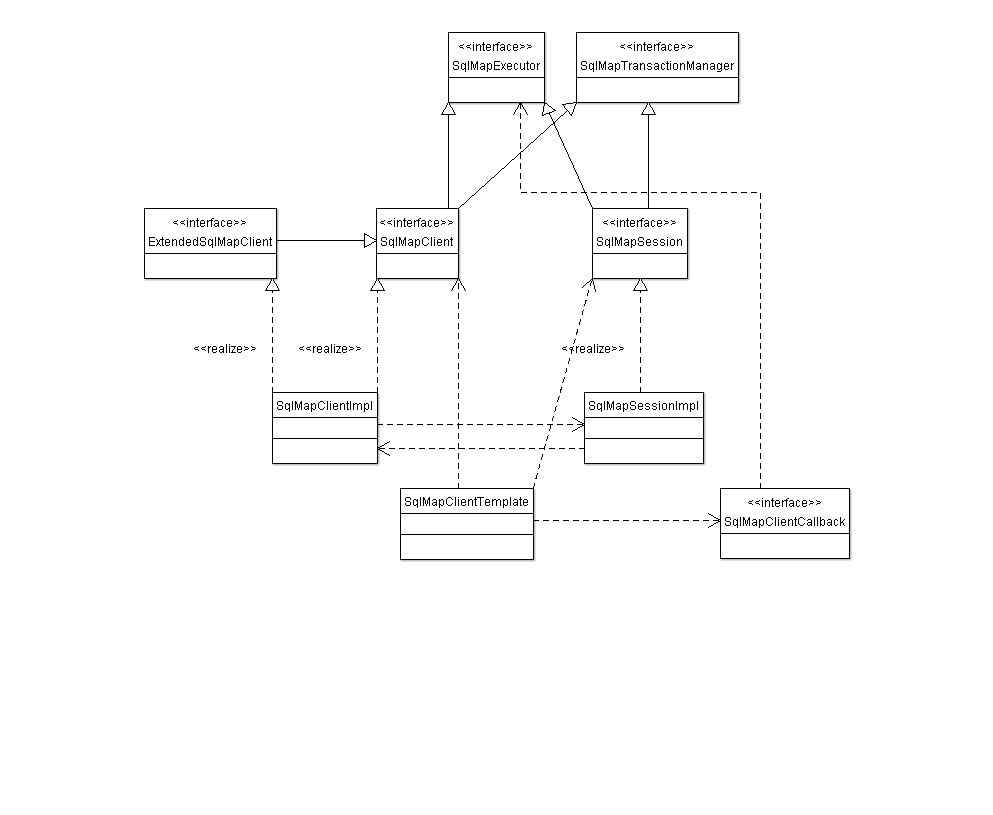
改造后的类图
从这两张图上可以看出shardbatis里新增了接口SqlMapShardingExt,SqlMapShardingExt中具体的方法如下
这里再通过实例简单介绍一下使用DefaultShardingStrategy时对sql的convert结果
比如sqlmap中定义的原始sql为:
实现自己的sharding策略,只要实现一个简单的接口即可
下面开始编码
4 楼 J-catTeam 2010-09-01 数据库的水平切分 使用局限性还是有的。比如sql中的分组,排序,或者其他一些情况。
另外 兄弟 你的测试方法应该不是很可靠吧。
5 楼 SeanHe 2010-09-01 J-catTeam 写道数据库的水平切分 使用局限性还是有的。比如sql中的分组,排序,或者其他一些情况。
另外 兄弟 你的测试方法应该不是很可靠吧。
数据库水平切分是有特定的场景的,我做这个的目的不是为了解决水平切分的局限性。我做这个的目的是为了通过ibatis实现数据库水平切分的功能。
至于测试方法有不可靠的地方请您不吝赐教,谢谢! 6 楼 J-catTeam 2010-09-01 SeanHe 写道J-catTeam 写道数据库的水平切分 使用局限性还是有的。比如sql中的分组,排序,或者其他一些情况。
另外 兄弟 你的测试方法应该不是很可靠吧。
数据库水平切分是有特定的场景的,我做这个的目的不是为了解决水平切分的局限性。我做这个的目的是为了通过ibatis实现数据库水平切分的功能。
至于测试方法有不可靠的地方请您不吝赐教,谢谢!
也没有什么赐教的哈,分库分表的前提是在大数据量的前提下的。 7 楼 SeanHe 2010-09-01 J-catTeam 写道SeanHe 写道J-catTeam 写道数据库的水平切分 使用局限性还是有的。比如sql中的分组,排序,或者其他一些情况。
另外 兄弟 你的测试方法应该不是很可靠吧。
数据库水平切分是有特定的场景的,我做这个的目的不是为了解决水平切分的局限性。我做这个的目的是为了通过ibatis实现数据库水平切分的功能。
至于测试方法有不可靠的地方请您不吝赐教,谢谢!
也没有什么赐教的哈,分库分表的前提是在大数据量的前提下的。
呵呵,我这里的对比测试只是为了说明加上sharding功能以后对ibatis本身性能的影响,而不是测试大数据量下sql的性能,大数据量的性能说白了和shardbatis或者和ibatis都没有什么关系 8 楼 lgdlgd 2010-09-01 我没有用过IBATIS,但最近研究了Hibernate shard这个项目,Hibernate shard没有解决分组、排序,分页用的是应用层面的内存分页,聊胜于无吧,不知道兄弟在这方面解决得如何 9 楼 forthelichking 2010-09-01 比较支持这种增强行为,特别是在已经上线的项目里且用上了ibatis后,干净地增加了分表分库的能力,为以后的可维护性大大增强。
不过我觉得这种直接增加方法的方式有点繁琐了,dao最好是直接能用上ibatis原有的sqlMapClient提供的dao方法,这样一来,只用改动配置,不用改动代码,就能直接实现分库分表的逻辑,对于dao开发者来说,他根本无需关心数据库是否分库分表了,展现给他的操作逻辑就是一个库,一个表。
ps:最好是能把读写分离的逻辑也能干净地整合进去,之前的做法大部分人是用在spring事务里面配置readonly=true,不过互联网世界中压根就没有数据库事务的思想(严重影响性能),基本上用app的逻辑控制事务回滚之类的。 10 楼 SeanHe 2010-09-01 forthelichking 写道比较支持这种增强行为,特别是在已经上线的项目里且用上了ibatis后,干净地增加了分表分库的能力,为以后的可维护性大大增强。
不过我觉得这种直接增加方法的方式有点繁琐了,dao最好是直接能用上ibatis原有的sqlMapClient提供的dao方法,这样一来,只用改动配置,不用改动代码,就能直接实现分库分表的逻辑,对于dao开发者来说,他根本无需关心数据库是否分库分表了,展现给他的操作逻辑就是一个库,一个表。
ps:最好是能把读写分离的逻辑也能干净地整合进去,之前的做法大部分人是用在spring事务里面配置readonly=true,不过互联网世界中压根就没有数据库事务的思想(严重影响性能),基本上用app的逻辑控制事务回滚之类的。
非常感谢你的鼓励
关于你第一点的建议这个我不是没有考虑过,但是即使基于sqlmapclient现有的api也很难做到开发人员在开发时不去关心如何分表。打个比方说如果不做分表是直接存放在表(sub_table)中,调用sqlmapclient的insert方法是传递的参数可能直接用SubTable这个pojo。但是如果这个应用要根据数据产生的时间按月分表,这个时候仅靠pojo里的参数就不够了。因此我就新开了方法来做sharding的功能。不过我刚才考虑了一下可能很多时候靠sqlmapclient原有的api和外加一些配置是可以完成sharding功能的。这个可以做后新的特性在后面的版本中实现。谢谢你的建议。
至于你提到的第二点我理解的是不是你说的读写分库?关于数据库路由的功能准备在后面版本里加,在rodemap里我也写了,具体的实现方式欢迎您一起讨论,谢谢。 11 楼 yangguo 2010-09-01 比较牛。轮子上加个胎或绣朵花才是正途。 12 楼 argan 2010-09-02 以前我也参考hibernate-sharding的思路做过一个封装 http://code.google.com/p/ibatis-sharding/
目标是尽量保持原来ibatis的使用习惯,功能和hibernate-sharding类似,很久没维护了,有兴趣的可以看看,代码也很简单 13 楼 sdh5724 2010-09-02 哈哈, 直接在JDBC上做WRAPER的话, 会更干净~ 14 楼 SeanHe 2010-09-02 sdh5724 写道哈哈, 直接在JDBC上做WRAPER的话, 会更干净~
大牛,果然就是大牛,一句话就给出了很好的解决方案。
让我开阔了思路。通过在sqlmap的xml里添加配置,程序的处理通过对jdbc的包装来处理。 15 楼 Angi 2010-09-26 请问可以支持分页查询吗?
如果不支持,有这方面的计划吗?
谢谢! 16 楼 SeanHe 2010-09-28 我个人认为如果对水平切分的数据要进行分页查询的话,可能会带来一些性能问题,可能最后没有了水平切分带来的优势。我觉的如果对水平切分的数据还要做分页查询的话,那还不如不要切分,可以选用其他的技术方案。比如说利用搜索引擎等 17 楼 sdh5724 2010-09-28 SeanHe 写道我个人认为如果对水平切分的数据要进行分页查询的话,可能会带来一些性能问题,可能最后没有了水平切分带来的优势。我觉的如果对水平切分的数据还要做分页查询的话,那还不如不要切分,可以选用其他的技术方案。比如说利用搜索引擎等
如果你在一家小公司, 拥有数十亿的数据, 有比较大的访问要求, 买不起昂贵的存储, 买不起昂贵的小鸡。 你会怎么做? 搜索引擎。。。OPENSOURCE的, 有几个能处理大规模索引的? 18 楼 myreligion 2010-09-28 sdh5724 写道SeanHe 写道我个人认为如果对水平切分的数据要进行分页查询的话,可能会带来一些性能问题,可能最后没有了水平切分带来的优势。我觉的如果对水平切分的数据还要做分页查询的话,那还不如不要切分,可以选用其他的技术方案。比如说利用搜索引擎等
如果你在一家小公司, 拥有数十亿的数据, 有比较大的访问要求, 买不起昂贵的存储, 买不起昂贵的小鸡。 你会怎么做? 搜索引擎。。。OPENSOURCE的, 有几个能处理大规模索引的?
那也要比select count(*) 数十亿数据来的快吧?如果分表,就不能多表联合查询了,要不分表还有什么意义。对于分页,应该通过分表的策略,让可能分页查询的数据都尽量在一个小表中。如果不能做到,或者单独计数,或者就不提供这种功能。 19 楼 linliangyi2007 2010-09-28 myreligion 写道sdh5724 写道SeanHe 写道我个人认为如果对水平切分的数据要进行分页查询的话,可能会带来一些性能问题,可能最后没有了水平切分带来的优势。我觉的如果对水平切分的数据还要做分页查询的话,那还不如不要切分,可以选用其他的技术方案。比如说利用搜索引擎等
如果你在一家小公司, 拥有数十亿的数据, 有比较大的访问要求, 买不起昂贵的存储, 买不起昂贵的小鸡。 你会怎么做? 搜索引擎。。。OPENSOURCE的, 有几个能处理大规模索引的?
那也要比select count(*) 数十亿数据来的快吧?如果分表,就不能多表联合查询了,要不分表还有什么意义。对于分页,应该通过分表的策略,让可能分页查询的数据都尽量在一个小表中。如果不能做到,或者单独计数,或者就不提供这种功能。
个人认为,分表分库不是用来做搜索的。更多用于服务器的负载均衡,我们也在iBatis基础上,结合spring实现了分库(保留分表的后期改造能力)。从性能上讲,分库(使用不同的物理服务器)视乎更好一些。 20 楼 linliangyi2007 2010-09-28 这样架构的前提大多针对特定的互联网应用,如SNS系统,有较强的针对性,而不去考虑多表的join和分页这种问题 21 楼 lishuaibt 2010-09-29 J-catTeam 写道数据库的水平切分 使用局限性还是有的。比如sql中的分组,排序,或者其他一些情况。
另外 兄弟 你的测试方法应该不是很可靠吧。
水平切分是会带来一些问题,但是既然我们已经做了水平切分,那么肯定是要牺牲一些东西的,比如数据库表的设计可能会反范式设计,简单的多表关联查询可能就没办法用了,诸如此类的问题,都会有。但是为了达到能容纳更多数据的目的,我觉得这样的牺牲是必要的。水平切分之后,我的理解就是其实RDBMS已经没有了关系,DB仅仅充当了Table的容器而已。如果还要使用关系的话,那么必然会给今后的扩展留下隐患。像时下流行的Key-Value系统,实现了什么?对外暴露出来的功能简单的就如同一个Map,但是确实是能解决一些问题的。是吧! 22 楼 SeanHe 2010-09-29 lishuaibt 写道J-catTeam 写道数据库的水平切分 使用局限性还是有的。比如sql中的分组,排序,或者其他一些情况。
另外 兄弟 你的测试方法应该不是很可靠吧。
水平切分是会带来一些问题,但是既然我们已经做了水平切分,那么肯定是要牺牲一些东西的,比如数据库表的设计可能会反范式设计,简单的多表关联查询可能就没办法用了,诸如此类的问题,都会有。但是为了达到能容纳更多数据的目的,我觉得这样的牺牲是必要的。水平切分之后,我的理解就是其实RDBMS已经没有了关系,DB仅仅充当了Table的容器而已。如果还要使用关系的话,那么必然会给今后的扩展留下隐患。像时下流行的Key-Value系统,实现了什么?对外暴露出来的功能简单的就如同一个Map,但是确实是能解决一些问题的。是吧!
是的,我也是认为水平切分是有特定的应用场景的。如果要和其他表做关联或者做分页查询那是用水平切分就不是最好的解决方案了