And-split,Or-split,And-join,Or-join随机组合后会有怎样的结果?
(我贴在Fire workflow 官方论坛www.fireflow.org里的帖子,copy到这里来接受拍砖)
以前写工作流引擎的时候,最让我困惑的是And-Split,Or-Split,And-Join,Or-Join这么几个流程模式的算法问题。这几个模式的概念当然非常清晰,单个看,其算法也较简单。问题是,如果这些模式随机的组合在一个很大很复杂的流程中,引擎如何保证能够正确的进行逻辑计算?我感觉很少有工作流引擎将这个问题说清楚。
在学习petrinet之前,我实在想不出一个好的算法解决这个问题,因为我的思维被限制在“全局控制”这样一个概念里面。也就是说,engine要能够正确的计算,必须知晓所有的状态。如下图1:如果对"And-join"节点进行汇聚计算,那么引擎必须知晓Or-Join,Activity3,Activity4当前的状态。由于流程的各个分支执行进度不一样,有的快有的慢,所以Or-Join,Activity3,Activity4的当前状态不一定都存在;另一方面,Or-Join,Activity3,Activity4代表的流程分支有可能并不需要执行(例如其转移条件计算结果为false,则对应的流程分支就不会执行),这种情况也会导致Or-Join,Activity3,Activity4的当前状态不一定都存在。这两种情况下,And-Join触发的时机是不一样的 。在第一中情况下 And-Join要继续等待,在第二种情况下,And-Join因该被触发。engine要何区分这两中情况,必须有某种机制知晓当前的“全局”状态,说实在的,我想不出好的机制做到这一点。更何况加入中国特色的流程操作,如自由流、撤销、退回等等的情况下,知晓全局状态更加困难。
图1: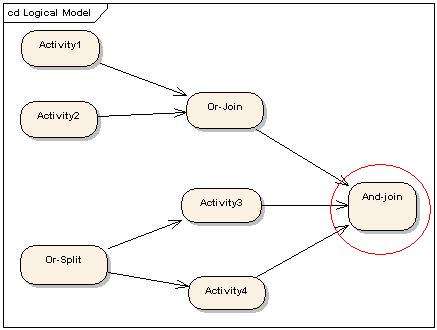
在Fire Workflow中,采用的是“局部控制”(petrinet的运行就是局部控制,理解错了请专家拍砖)。首先,在Fire workflow中,Synchronizer代表工作流子系统的计算逻辑,对应petriNet中的T,所有的分支/汇聚都是由Synchronizer完成。按照PetriNet的定义,Synchronizer的触发条件是:图2,图中act是fire workflow中的activity,相当于PetriNet的S;sync为fire workflow的synchronizer,相当于petriNet的T。而实际的设计中没有搞得那么复杂,Synchronizer的定义的触发条件很简单,就是:token-count-of (Synchronizer)=volume-of (Synchronizer),通俗解释就是Synchronizer当前获得的token数量等于Synchronizer的容量(本来T无容量的概念,我这样变通一下应该是合理的)。
图2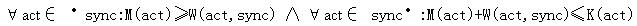
同时Fire Workflow规定:
1、Synchronizer的容量=输入Transition的数量 * 输出Transition的数量;
2、Synchronizer输入Transition的权 = Synchronizer的容量 / 输出Transition的数量
3、Synchronizer输出Transition的权 = Synchronizer的容量 / 输入Transition的数量
4、Fire workflow 工作流逻辑的执行不受业务逻辑的影响,即,即使某个transition的条件计算结果为false,也不影响token继续向前传递。(实际上这个不是Fire workflow的规定,为了便于理解,我且这么说吧)
通过上面的各种规定,我们看一下Fire workflow中,Join是如何实现的,如下图3。在该图中S的容量是6,t1,t2,t3的权重都是2,t4,t5的权都是3。那么S汇聚的算法就是:当他收到的Token数量等于6时触发。S一定会收到6个token吗?一定会!根据上面的第4条规定,t1,t2,t3一定会被执行,只是迟早的问题。t1,t2,t3执行后,根据PetriNet的规则,恰好给S带来6个token。也可以看出在Fire workflow中,join的执行不需要了解这个网络当前的状态,只要知道他自己的状态(收到的token数量)即可。
实际上在Fire workflow 中,不必要区分And-Split, Or-Split,And-Join,一切都是Synchronizer,大家可以继续参阅文档《3_各种工作流模式的实现》的第4章“顺序、分支、汇聚”。在Fire workflow 中,没有Or-Join,我认为这个模式是不合理的,以后再论述,欢迎拍砖。
图3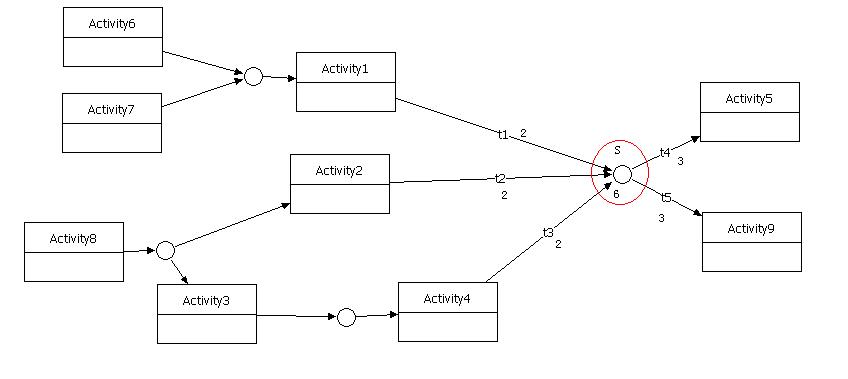

实现了。不知道你是否了解一些petrinet的东西,否则我不太好解释阿,一两句话也说不清楚。我记得在我的文档中说了这样的话“21种工作流模式看到了业务现象,没有看到问题的本质”,实际上从Fire workflow看来,没有必要把问题搞得那么复杂,诸如merge、multimerge等,fire workflow的synchronizer很智能,把这些罗罗嗦嗦的模式都囊括了。
为什么有这么只能,关键在于fire workflow把业务逻辑和工作流逻辑解耦,如何解耦?其实就在这篇帖子里面。或许写的还不够详细,欢迎继续交流。 3 楼 netren 2009-06-09 fire workflow也有自己的流程定义吧,这个逻辑是在流程定义中就描述出来吧?
4 楼 nychen2000 2009-06-09 netren 写道fire workflow也有自己的流程定义吧,这个逻辑是在流程定义中就描述出来吧?
Fire workflow 不需要在synchronizer这个节点上描述这个逻辑,它能够自己知道怎么汇聚,fire worklfow synchronizer做的一定是你想要的,所以fire workflow非常简单直观。 5 楼 netren 2009-06-09 关键是合并有多种,and join\or join \xor join
如果不在定义时描述出来,引擎根据什么解析呢? 6 楼 nychen2000 2009-06-09 netren 写道关键是合并有多种,and join\or join \xor join
如果不在定义时描述出来,引擎根据什么解析呢?
你的问题正是Fire workflow为什么宣称“有严密的理论作基础”,到目前为止我认为这个结论还是靠得住的。
我03年的时候写过一个工作流产品,遇到的就是这个问题无法攻克。现在的产品解决了这个问题主要体现在petri net理论和软件设计思想的结合。petri理论我就不多说了,设计思想就是刚才说的业务逻辑和工作流逻辑解耦。
在官方论坛上也有针对这个问题的讨论,你参考一下
http://www.fireflow.org/viewthread.php?tid=9&extra=page%3D1
另外,我还写了一个文档《fpdl对xpdl的扩展及其理由》,也论述到这个问题,不过这个文档暂时还没有贴上来,需要等一段时间再贴。
7 楼 netren 2009-06-09 那我就期待楼主的新作了,呵呵,
最近多有讨饶,在此谢过:) 8 楼 itstarting 2009-08-11 nychen2000 写道
S一定会收到6个token吗?一定会!
感觉有点武断,token传递部分请好好解释一下,包括token容量的问题,有空分析下相关代码
我是在工作流中为了简化图形元素,增加灵活度,定义了活动都具有路由(Routing)能力,增加Join完成策略和Split完成策略,这样就可以灵活支持AND/OR/XOR的JOIN/SPLIT了
唯一的问题还是难以实现很简单的计算算法,还是得依赖拓扑关系去“找”去算。 9 楼 comsci 2009-11-04 这个拓扑关系的计算是躲不掉的,一个简单的方法就是计算出流程图中任意两个节点的位置与相互关系,然后再应用其它办法解决
我对这个问题的初步解决方法,请看
JWFD工作流引擎设计中遇到的一个实际问题的解决方案,请参考我的博文"带条件选择的并行汇聚路由问题"中图例A2描述的情况 (http://comsci.iteye.com/blog/339756),我现在把我对图例A2的一个解决方案公布出来,请大家多指点
节点匹配搜索算法(用于解决标准对称流程图条件汇聚点运行控制参数的算法)
需要解决的问题:已知分支点的运行路径数值S,求流程图中一个汇聚点的实际访问(实际汇聚)数值,通过获取该数值,使得流程引擎控制器能够准确的控制流程的运转,即准确的控制对条件异步汇聚点放行的时机(对于该问题,国内另外一个开源工作流 Fireworkflow的作者非也有另外一个思路 请参考 http://www.fireflow.org/viewthread.php?tid=9&extra=page%3D3 )
算法设计思路: 对于标准的对称的流程图而言,一个汇聚点一般来讲是应该对应一个分支点的,也就是说汇聚支路数应该和它前面的分支支路数相吻合(当然,这只是对很规则的对称流程图模型来讲),那么如果在分支节点中如果出现了条件选择公式(或者智能脚本),那么从这个分支节点所分出来的支路,就不一定都会被选中(简单举例, 我们在分支节点中嵌入了一个条件表达式a>2,那么如果分支实际有三条支路,在流程运行过程中,a的数值大于2,符合嵌入的条件,三条支路其中的2 条就会运行下去,而另外一条就不会运行,这样一来,在该节点的后驱汇聚点那里,我们就需要知道具体运行下去的支路数到底是几条? 怎么才能够获取这个支路数呢? 我们在流程运行控制器(流程引擎)中加入一段算法,使得我们确定的知道一个条件汇聚点的前驱分支点是哪个节点,然后我们先计算一次嵌入条件公式,预先知道该前驱分支点具体要走几条支路,然后再把这个支路数值作为参数传递给用于控制条件汇聚点的控制器中,使得汇聚点按照实际运行的支路来判断是否该继续运行到下一个节点去,那么我们按照这个思路设计伪代码算法
混合伪代码5步描述法
1: 条件表达式解析函数 public java.util.ArrayList CFS(SID,GID)()
这个函数是流程控制器中用于解析流程嵌入的条件表达式,并根据流程的变量数值计算出流程嵌入公式的结果,函数参数SID是传递给流程控制器中的需要处理的节点ID,GID是流程图的ID,下面一致
2: 获取输入汇聚节点的所有前驱汇聚点函数 public java.util.ArrayList GAS(SID,GID)() 这个函数用于获取该节点前面出现的所有汇聚点
3: 获取输入汇聚节点的所有前驱分支点函数 public java.util.ArrayList GAJ(SID,GID)() 这个函数用于获取该节点前面出现的所有分支点
4: 对该节点的所有前驱分支点集合和前驱汇聚点集合进行计算,找出该汇聚节点的匹配分支点SSID public String GRN(GAS,GAJ,GID)() 节点匹配算法的实质是对称集合配对差算法
5: 在找到这个匹配的分支点SSID之后,我们就可以对其中嵌入的条件公式进行提前计算
public int PCSF(SSID,GID)(
CFS(SSID,GID)()
return K;
)
这样获得了一个int数值k,然后我们就在流程控制器中在流程汇聚点进行控制的过程中使用这个数值,那么前面提到得问题就这样初步解决了,离圆满的解决这个问题,我们又近了一步............
更多文章请到我的博客中查看 comsci.iteye.com
10 楼 comsci 2010-03-11 “engine要何区分这两中情况,必须有某种机制知晓当前的“全局”状态,说实在的,我想不出好的机制做到这一点。更何况加入中国特色的流程操作,如自由流、撤销、退回等等的情况下,知晓全局状态更加困难。 ”
这个问题就我们目前研究的情况来看,要使得流程系统准确而及时的运转下去,能够按照预先设定的方案正确的流转下去,肯定是要知晓全局的状态的,如果不清楚全局的状态,肯定是无法把握单一节点的运行走向的。。。。请非也兄指教 11 楼 comsci 2010-03-22 一个运行中的流程,从开始到结束,始终是一个在时间和空间上面连续的整体过程,因此基于这点,我们设计引擎的时候,特别核心控制器的时候,必须从整体上面来把握