hadoop初识--HelloHadoopV1
/**
?* HelloHadoop
?* 此程序用来了解Hadoop的<key,value>,并且练习hadoop api 编程
?*
?* 测试方法:
?* 1、将该程序打包在hadoop0.21.0平台上;打成jar包,并将jar包拷贝到usr/local/hadoop(hadoop的安装目录)下
?* 2、格式化namenode:
?* hadoop@wxy:/usr/local/hadoop$ ./bin/hadoop namenode -format
?* 3、启动hadoop
?* hadoop@wxy:/usr/local/hadoop$ ./bin/start-all.sh
?* 4、查看hadoop运行情况 ¥jps
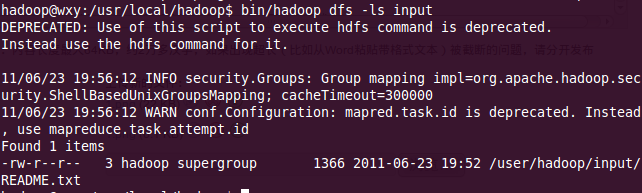
?* 5、在hdfs上创建input文件夹,将文本文件READ.TXT拷贝到hdfs(/user/hadoop/input)上

? 
?
?* 6执行:
?* hadoop@wxy:/usr/local/hadoop$ bin/hadoop jar HelloHadoop.jar
?*7 查看运行结果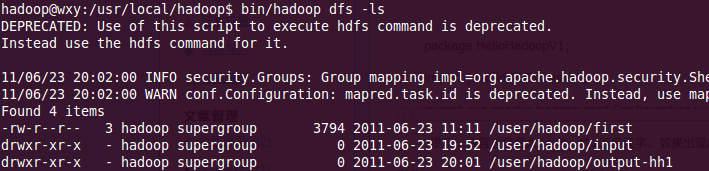
?如上图,产生/user/hadoop/output-hh1文件夹,文件夹中包含运行结果
?
?*
?*注意:
?*1.在hdfs 上来源文档路径为 "/user/hadoop/input"
?*? 注意必须先放资料到此hdfs上的文件夹内,且文件夹内只能放文件,不能再放文件夹?????
?*2. 运算完后,程序将执行结果放在hdfs 的输出路径为 "/user/$YOUR_NAME/output-hh1"
?*? 注意此文件夹为运算结束后才产生的,所以运算之前不会产生该文件夹??
?*?
?*浏览器中输入:http://localhost:50030/jobtracker.jsp查看运行状态
?*/
?
?
package HelloHadoopV1;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/** * HelloHadoop * @author wxy * 此程序用来了解Hadoop的<key,value>,并且练习hadoop api 编程 * */public class HelloHadoop {static public class HelloMapper extends Mapper<LongWritable,Text,LongWritable,Text>{public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException {//将输入的资料,原封不动的写入输出context.write((LongWritable)key, (Text)value);}}static public class HelloReducer extends Reducer<LongWritable,Text,LongWritable,Text>{public void reduce(LongWritable key,Iterable<Text> values,Context context) throws IOException,InterruptedException {Text val = new Text();//取得values的值,放入val中for(Text str:values){val.set(str.toString());}//将获取的资料引入输出context.write(key, val);}}public static void main(String[] args)throws IOException,InterruptedException,ClassNotFoundException{//引入 ¥HADOOP_HOME/conf 启用默认配置Configuration conf = new Configuration();//定义一个job,宣告job取得conf并设定名称 Hadoop Hello WorldJob job = new Job(conf,"Hadoop Hello World");//设置运算主程序,即执行类job.setJarByClass(HelloHadoop.class);//设置输入路径FileInputFormat.setInputPaths(job,"input");//设置输出路径FileOutputFormat.setOutputPath(job,new Path("output-hh1"));//指定Map class,即设定Mapper的实现类job.setMapperClass(HelloMapper.class);//指定reduce class,即设定Reducer的实现类job.setReducerClass(HelloReducer.class);//开始运算job.waitForCompletion(true);}}