map的环形内存缓冲区
hadoop在执行MapReduce任务时,在map阶段,map函数产生的输出,并不是直接写入磁盘的。为了提高效率,它将输出结果先写入到内存中(即环形内存缓冲区,默认大小100M),再从缓冲区(溢)写入磁盘。
下面我们就来看看这段代码。
1、找到环形内存缓冲区
在运行job时,有条输出:
09/04/07 12:34:35 INFO mapred.MapTask: io.sort.mb = 100
上面的io.sort.mb,即map环形内存缓冲区的大小。
在org.apache.hadoop.mapred.MapTask中的第764行找到“io.sort.mb”
第781行:
kvbuffer = new byte[maxMemUsage - recordCapacity];
private byte[] kvbuffer; // main output buffer
第762行:final float spillper = job.getFloat("io.sort.spill.percent",(float)0.8);// 溢写比:默认是0.8,就是说,缓存区80%满了的时候,就要将数据从内存溢写到磁盘了这100M,还分成2块:数据缓存和记录缓存第707行:private final int[] kvoffsets; // indices into kvindices// 这个int型的数组就是记录缓存第941行: // sort by key return comparator.compare(kvbuffer, kvindices[ii + KEYSTART], kvindices[ii + VALSTART] - kvindices[ii + KEYSTART], kvbuffer, kvindices[ij + KEYSTART], kvindices[ij + VALSTART] - kvindices[ij + KEYSTART]);// 在内存缓冲区中按key进行排序综上,溢写发生在:第1038行:boolean buffull = false; // 缓存是否满了 // 这里的“满”,有2种情况:1) bufindex + len > bufvoid// 就是说,达到了末尾// 但是这种情况,可能不是真的满了// 因为,在数组0-bufstart之间,可能还有很大的空置空间2) bufindex + len > bufstart// 由于缓冲区已经成“环”,这种情况,是真的满了。第1039行:boolean wrap = false;// 是否需要“折行写”// “折行写”的条件:1) bufstart <= bufend && bufend <= bufindex// buffer是一段连续的区域,还没有形成“环”2) (bufvoid - bufindex) + bufstart > len// 数组末尾,加上数组开头的空间能够存储当前数据// 真正执行“折行写”的代码(Line1101-1107):if (buffull) { // 这里满足上面第1种buffull = true的条件,否则// 将先溢写至磁盘后,再到达这里。 final int gaplen = bufvoid - bufindex; System.arraycopy(b, off, kvbuffer, bufindex, gaplen); len -= gaplen; off += gaplen; bufindex = 0; }Line996-1014的reset()方法:这个方法被调用的地点:第895行, 第893行,在collect方法中: if (bufindex < keystart) { // wrapped the key; reset required bb.reset(); keystart = 0; }// 如果key被“折写”成2段,则reset缓冲区// 这时候:一个key有一半写在了数组末尾,另一半写在了数组列头时候这个方法被调用的时候(bufindex < keystart == true):一定是,序列化后的key被写入缓存区,而且是被wrap(折行)写入的!这个方法里的解释: protected synchronized void reset() throws IOException { // spillLock unnecessary; If spill wraps, then // bufindex < bufstart < bufend so contention is impossible // a stale value for bufstart does not affect correctness, since // we can only get false negatives that force the more // conservative path int headbytelen = bufvoid - bufmark;// headbytelen的意思是:被“折行”写入的key的前段部分// bufvoid是缓冲区的右边界// bufmark是缓冲区中上次存值后的右边界// bufvoid - bufmark :就是被“折行”写入的key的前半段 bufvoid = bufmark; if (bufindex + headbytelen < bufstart) { // 基本上这个条件成立的可能性比较大, // 它的意思是说:整个key的长度(前半段的长度是headbytelen,存在缓冲区最后面;后半段的长度是bufindex,存在缓冲区的最前面)在bufstart之间的空间能存得下 // 那么接下来的2行代码:把这个key的两端,都移到缓冲区的最前面! System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex); System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen); bufindex += headbytelen; } else { // 这种情况真的很难达到:要求溢写比(io.sort.spill.percent)为1,并且bufstart很靠近0的时候 // 这种情况是:buffer真的很满了(bufstart-bufindex<headbytelen),以至于在bufstart之前的空间不足以存储一个key byte[] keytmp = new byte[bufindex]; System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex); bufindex = 0; // 把这个key分2次写入out // 也就是说: // 1) 这个key,先从kvbuffer缓存中删除 // 2) 接下来,应该是将缓存中数据溢写到磁盘上 // 3) out中的这个key再次写入清空后的缓存里! // 估计在清空缓存前,这个都会被阻塞。 out.write(kvbuffer, bufmark, headbytelen); out.write(keytmp); } } }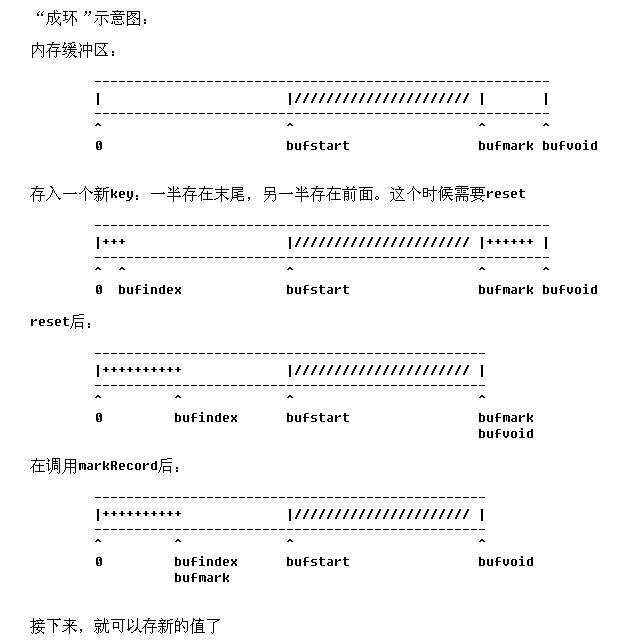
bufend = bufmark; // 在startSpill方法中sortAndSpill();bufstart = bufend;
解读“溢写”代码:bufend = bufmark; // 在startSpill方法中sortAndSpill();bufstart = bufend;1)溢写前:bufend = bufmark;则溢写的范围是:从bufstart到bufend。2)在溢写的过程中,bufmark还是有可能增长的!3)溢写完毕,bufstart = bufend;