如何提高Java 多线程应用性能(转)
?
当 CPU 进入多核时代之后,软件的性能调优就不再是一件简单的事情。没有并行化的程序在新的硬件上可能会运行得比从前更慢。当 CPU 数目增加的时候,芯片制造商为了取得最佳的性能/功耗比,降低 CPU 的运行频率是一件非常明智的事情。相比 C/C++ 程序员而言 , 利用 Java 编写多线程应用已经简单了很多。然而,多线程程序想要达到高性能仍然不是一件容易的事情。对于软件开发人员而言, 如果在测试时发现并行程序并不比串行程序快,那不是一件值得惊讶的事情,毕竟,在多核时代之前, 受到广泛认可的并行软件开发准则通常过于简单和武断。
在本文中,我们将介绍提高 Java 多线程应用性能的一般步骤。 通过运用本文提供的一些简单规则,我们就能获得具有高性能的可扩展的应用程序。
?
作为追求完美的软件工程师,我们希望看到随着线程数目的增长程序的性能获得线性的增长,也就是图 1 中的蓝色直线。而我们最不希望看到的是绿色的曲线,不管投入多少新的 CPU,性能也没有丝毫增长。(随着 CPU 增长而性能下降的曲线在实际项目中也存在)。而图中的红色线条则说明通常的 90-10 法则并不适用于可扩展性方面。假设程序中有 10% 的计算只能串行进行,那么其扩展性曲线如红线所示。由图可见,当 90% 的代码可以完美的并行时,在 10 个 CPU 存在的情况下,我们也只能获得大约 5 倍的性能。如果任务中具有无法并行的部分,那么在现实世界,我们的性能曲线大致上会位于图 1 中的灰色区域。
在这篇文章中,我们不会试图挑战理论极限。我们希望能解释一个 Java 程序员如何能够尽可能的接近极限,这已经不是一个容易的任务。
?
在上图中,蓝色的曲线是一个基于 Lock 的老式日志服务器,而绿色的曲线是我们进行了性能调优之后的日志服务器。可以看到,LogServerBad 的性能随线程数目的增加变化很小,而 LogServerGood 的性能则随着线程数目的增加而线性增长。如果不介意使用第三方的库的话,那么来自 Project KunMing 的 LockFreeQueue 可以进一步提供更好的可扩展性:
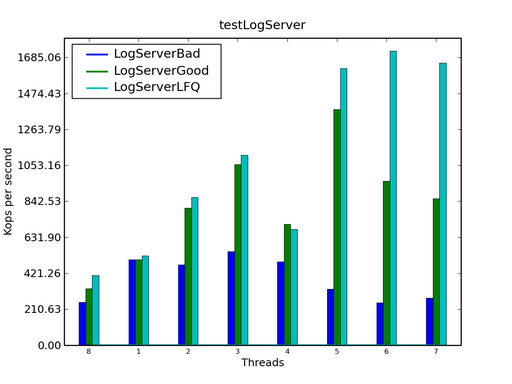 ?
?在上图中,第三条曲线表示用 LockFreeQueue 替换标准库中的 ConcurrentLinkedQueue 之后的性能曲线。可以看到,如果线程数目较少时,两条曲线差别不大,但是单线程数目增大到一定程度之后,Lock-Free 的数据结构具有明显的优势。
在下文中,将介绍在上述例子中使用的可以帮助我们创建高可扩展 Java 应用的工具和技巧。
使用 JLM 分析应用程序
JLM 提供了 Java 应用和 JVM 中锁持有时间和冲突统计。具体提供以下功能:
使用 AtomicInteger 进行计数
通常,在我们实现多线程使用的计数器或随机数生成器时,会使用锁来保护共享变量。这样做的弊端是如果锁竞争的太厉害,会损害吞吐量,因为竞争的同步非常昂贵。
volatile 变量虽然可以使用比同步更低的成本存储共享变量,但它只可以保证其他线程能够立即看到对 volatile 变量的写入,无法保证读 - 修改 - 写的原子性。因此,volatile 变量无法用来实现正确的计数器和随机数生成器。
从 JDK 5 开始,java.util.concurrent.atomic?包中引入了原子变量,包括 AtomicInteger、AtomicLong、AtomicBoolean 以及数组 AtomicIntergerArray、AtomicLongArray 。原子变量保证了?++,--,+=,-=?等操作的原子性。利用这些数据结构,您可以实现更高效的计数器和随机数生成器。
加入轻量级的线程池―― Executor
大多数并发应用程序是以执行任务(task)为基本单位进行管理的。通常情况下,我们会为每个任务单独创建一个线程来执行。这样会带来两个问题:一,大量的线程(>100)会消耗系统资源,使线程调度的开销变大,引起性能下降;二,对于生命周期短暂的任务,频繁地创建和消亡线程并不是明智的选择。因为创建和消亡线程的开销可能会大于使用多线程带来的性能好处。
一种更加合理的使用多线程的方法是使用线程池(Thread Pool)。 java.util.concurrent 提供了一个灵活的线程池实现:Executor 框架。这个框架可以用于异步任务执行,而且支持很多不同类型的任务执行策略。它还为任务提交和任务执行之间的解耦提供了标准的方法,为使用 Runnable 描述任务提供了通用的方式。 Executor 的实现还提供了对生命周期的支持和 hook 函数,可以添加如统计收集、应用程序管理机制和监视器等扩展。
在线程池中执行任务线程,可以重用已存在的线程,免除创建新的线程。这样可以在处理多个任务时减少线程创建、消亡的开销。同时,在任务到达时,工作线程通常已经存在,用于创建线程的等待时间不会延迟任务的执行,因此提高了响应性。通过适当的调整线程池的大小,在得到足够多的线程以保持处理器忙碌的同时,还可以防止过多的线程相互竞争资源,导致应用程序在线程管理上耗费过多的资源。
Executor 默认提供了一些有用的预设线程池,可以通过调用 Executors 的静态工厂方法来创建。
使用并发数据结构
Collection 框架曾为 Java 程序员带来了很多方便,但在多核时代,Collection 框架变得有些不大适应。多线程之间的共享数据总是存放在数据结构之中,如 Map、Stack、Queue、List、Set 等。 Collection 框架中的这些数据结构在默认情况下并不是多线程安全的,也就是说这些数据结构并不能安全地被多个线程同时访问。 JDK 通过提供 SynchronizedCollection 为这些类提供一层线程安全的接口,它是用?synchronized?关键字实现的,相当于为整个数据结构加上一把全局锁保证线程安全。
java.util.concurrent 中提供了更加高效 collection,如 ConcurrentHashMap/Set, ConcurrentLinkedQueue, ConcurrentSkipListMap/Set, CopyOnWriteArrayList/Set 。这些数据结构是为多线程并发访问而设计的,使用了细粒度的锁和新的 Lock-free 算法。除了在多线程条件下具有更高的性能,还提供了如 put-if-absent 这样适合并发应用的原子函数。
其他一些需要考虑的因素
不要给内存系统太大的压力
如果线程执行过程中需要分配内存,这在 Java 中通常不会造成问题。现代的 JVM 是高度优化的,它通常为每个线程保留一块 Buffer,这样在分配内存时,只要 buffer 没有用光,那么就不需要和全局的堆打交道。而本地 buffer 分配完毕之后 , JVM 将不得不到全局堆中分配内存,这样通常会带来严重的可扩展性的降低。另外,给 GC 带来的压力也会进一步降低程序的可扩展性。尽管我们有并行的 GC,但其可扩展性通常并不理想。如果一个循环执行的程序在每次执行中都需要分配临时对象,那么我们可以考虑利用 ThreadLocal 和 SoftReference 这样的技术来减少内存的分配。
使用 ThreadLocal
ThreadLocal 类能够被用来保存线程私有的状态信息,对于某些应用非常方便。通常来讲,它对可扩展性有正面的影响。它能为各个线程提供一个线程私有的变量,因而多个线程之间无须同步。需要注意的是在 JDK 1.6 之前,ThreadLocal 有着相当低效的实现,如果需要在 JDK 1.5 或更老的版本上使用 ThreadLocal,需要慎重评估其对性能的影响。类似的,目前 JDK 6 中的 ReentrantReadWriteLock 的实现也相当低效,如果想利用读锁之间不互斥的特性来提高可扩展性,同样需要进行 profile 来确认其适用程度。
锁的粒度很重要
粗粒度的全局锁在保证线程安全的同时,也会损害应用的性能。仔细考虑锁的粒度在构建高可扩展 Java 应用时非常重要。当 CPU 个数和线程数较少时,全局锁并不会引起激烈的竞争,因此获得一个锁的代价很小(JVM 对这种情况进行了优化)。随着 CPU 个数和线程数增多,对全局锁的竞争越来越激烈。除了一个获得锁的 CPU 可以继续工作外,其他试图获得该锁的 CPU 都只能闲置等待,导致整个系统的 CPU 利用率过低,系统性能不能得到充分利用。当我们遇到一个竞争激烈的全局锁时,可以尝试将锁划分为多个细粒度锁,每一个细粒度锁保护一部分共享资源。通过减小锁的粒度,可以降低该锁的竞争程度。 java.util.concurrent.ConcurrentHashMap 就通过使用细粒度锁,提高 HashMap 在多线程应用中的性能。在 ConcurrentHashMap 中,默认构造函数使用 16 个锁保护整个 Hash Map 。用户可以通过参数设定使用上千个锁,这样相当于将整个 Hash Map 划分为上千个碎片,每个碎片使用一个锁进行保护。
结论
通过选择一种合适的 profile 工具,检查 profile 结果中的热点区域。使用适合多线程访问的数据结构,线程池,细粒度锁减小热点区域。并重复此过程不断提高应用的可扩展性。
构建在多核上具有高可扩展性的 Java 应用并不是一件容易的事。减少各个线程之间的冲突和同步是提高可扩展性的关键。本文中介绍的一些通用工具和技巧可以给程序员提供一些帮助,但更多的情况要依赖于具体的应用。
?