细节优化提升资源利用率
1.?应用维度分析(应用的正常业务调用行为和异常调用行为分析)
2.?服务维度分析(服务RT,总量,成功失败率,业务错误及子错误等)
3.?平台维度分析(平台消耗时间,平台授权等业务统计分析,平台错误分析,平台系统健康指标分析等)
4.?业务维度分析(用户,应用,服务之间关系分析,应用归类分析,服务归类分析等)
上面只是一部分,从上面的需求来看需要一个系统能够灵活的运行期配置分析策略,对海量数据作即时分析,将接过用于告警,监控,业务分析。
?
下图是最原始的设计图,很简单,但还是有些想法在里面:
?
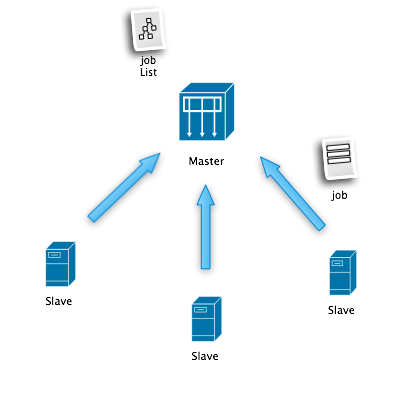
?
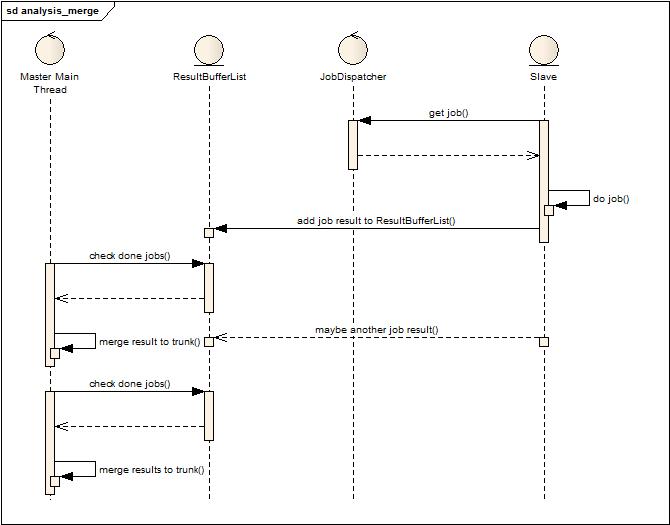
Master:管理任务(分析任务),合并结果(Reduce),输出结果(全量统计,增量片段统计)
Slave:Require Job + Do Job + Return Result,随意加入,退出集群。
Job:(Input + Analysis Rule + Output)的定义。
?
几个设计点:
1.??????????后台系统任务分配:无负载分配算法,采用细化任务+工作者按需自取+粗暴简单任务重置策略。
2.??????????Slave与Master采用单向通信,便于容量扩充和缩减。
3.??????????Job自描述性,从任务数据来源,分析规则,结果输出都定义在任务中,使得Slave适用与各种分析任务,一个集群分析多种日志,多个集群共享Slave。
4.??????????数据存储无业务性(意味着存储的时候不定义任何业务含义),分析规则包含业务含义(在执行分析的时候告知不同列是什么含义,怎么统计和计算),优势在于可扩展,劣势在于全量扫描日志(无预先索引定义)。
5.??????????透明化整个集群运行状况,保证简单粗暴的方式下能够快速定位出节点问题或者任务问题。(虽然没有心跳,但是每个节点的工作都会输出信息,通过外部收集方式快速定位问题,防止集群为了监控耦合不利于扩展)
6.??????????Master单点采用冷备方式解决。单点不可怕,可怕的是丢失现场和重启或重选Master周期长。因此采用分析数据和任务信息简单周期性外部存储的方式将现场保存与外部(信息尽量少,保证恢复时快速),另一方面采用外部系统通知方式修改Slave集群MasterIP,人工快速切换到冷备。
?
Master的生活轨迹:
?
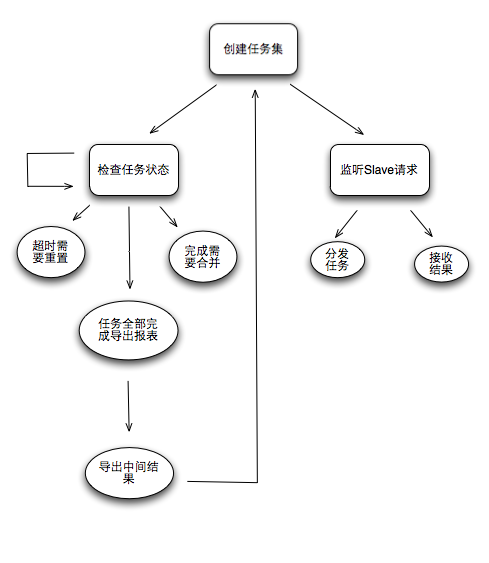
?
?
Slave的生活轨迹:
?
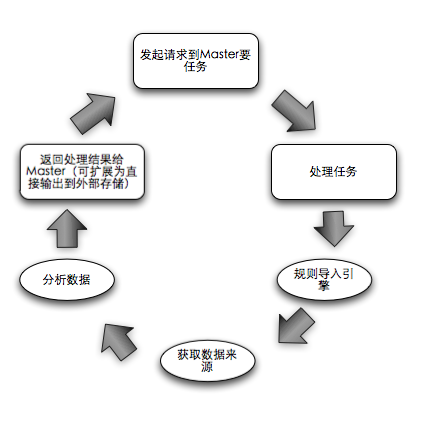
?
有人会觉得这玩意儿简单,系统就是简单+透明才会高效,往往就是因为系统复杂才会带来更多看似很高深的设计,最终无非是折腾了自己,苦了一线。废话不多说,背景介绍完了,开始讲具体的演变过程。
数据量:2千万 à 1亿 à 8亿 à15亿。报表输出结果:10份配置à30份à60份à100份。统计后的数据量:10k à 10M à 9G。统计周期的要求:1天à5分钟à3分钟à1分半。
从上面这些数据可以知道从网络和磁盘IO,到内存,到CPU都会经历很大的考验,由于Master是纵向扩展的,因此优化Master成为每个数据跳动的必然要求。由于是用Java写的,因此内存对于整体分析的影响更加严重,GC的停顿直接可以使得系统挂掉(因为数据在不断流入内存)。
?
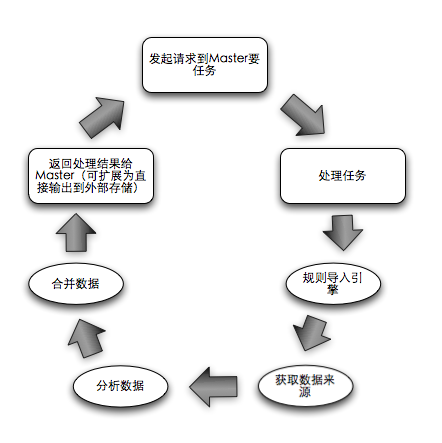
?
?
1.????不可逆数字摘要采样。
有点类似与短连接转换的方式,对数据做Md5数字摘要,获得16个byte,然后根据压缩配置来采样16个byte部分,用可见字符定义出64进制来标识这些采样,最后形成较短的字符串。
由于Slave是数据分析者,因此用Slave的CPU来换Master的内存,将中间结果用不可逆的短字符串方式表示。弱点:当最后分析出来的数据量越大,采样md5后的数据越少,越容易产生冲突,导致统计不准确。
?
2.????提供需要压缩的业务数据列表。
业务方提供日志中需要替换的列定义及一组定义内容。简单来说,当日志某一列可以被枚举,那么就意味者这一列可以被简单的替换成短标识。例如配置APIName这列在分析生成key的时候可以被替换,并且提供了500多个api的名称文件载入到内存中,那么每次api在生成key的时候就会被替换掉名称组合在key中,大大缩短key。那为什么要提供这些api的名称呢?首先分析生成key在Slave,是分布式的,如果采用自学习的模式,势必要引入集中式唯一索引生成器,其次还要做好足够的并发控制,另一方面也会由并发控制带来性能损耗。这种模式虽然很原始,但不会影响统计结果的准确性,因此在分析器中被使用,这个列表会随着任务规则每次发送到Slave中,保证所有节点分析结果的一致性。
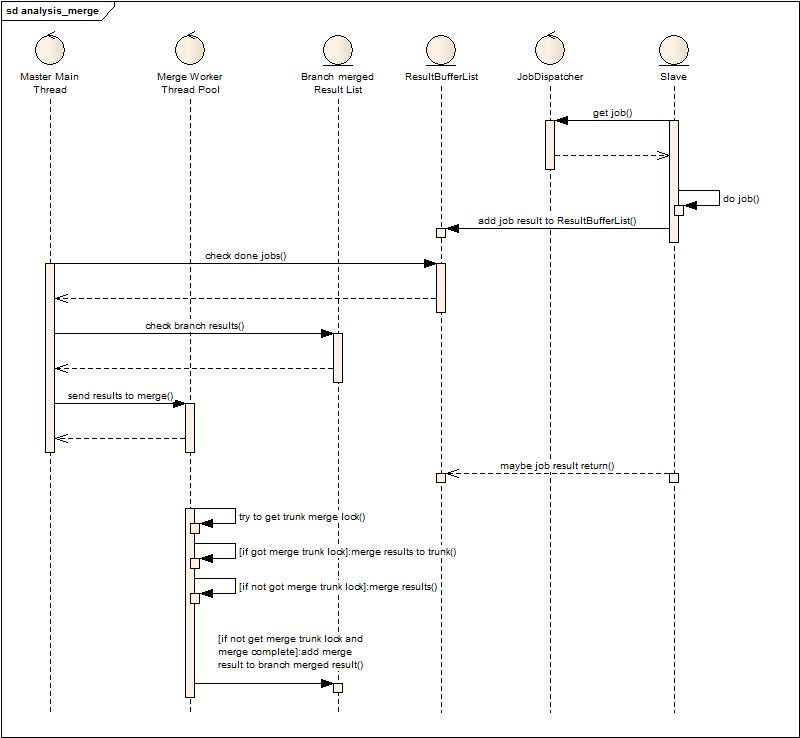
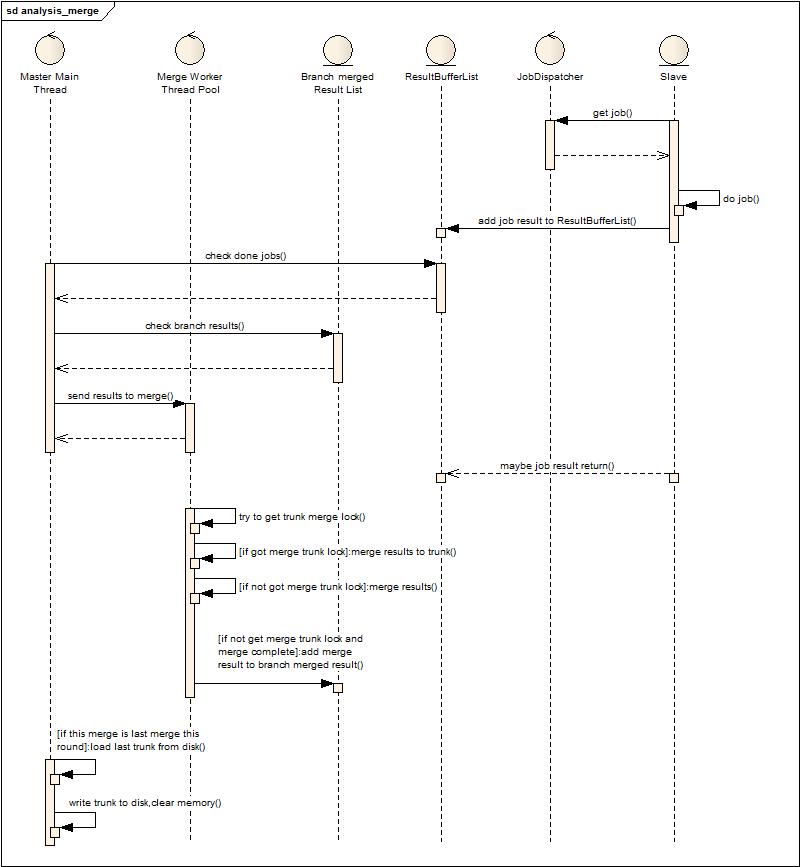
1.????利用可横向扩展的系统来分担纵向扩展系统的工作。
2.????流程中中间数据的优化处理。
3.????特殊化处理可以特殊处理的流程。
4.????从整体流程上考虑不同策略的消耗,提高整体处理能力。
5.????资源的快用快放,提高同一类资源利用率。
6.????不同阶段不同资源的互换,提高不同资源的利用率。
其实很多细节也许看了代码才会有更深的体会,分析器只是一个典型的消耗性案例,每一点改进都是在数据和业务驱动下不断的考验。例如纵向的Master也许真的有一天就到了它的极限,那么就交给Slave将数据产出到外部存储,交由其他系统或者另一个分析集群去做二次分析。对于海量数据的处理来说都需要经历初次筛选,再次分析,展示关联几个阶段,Java的应用摆脱不了内存约束带来对计算的影响,因此就要考虑好自己的顶在什么地方。但优化一定是全局的,例如磁盘换内存,磁盘带来的消耗在总体上来说还是可以接受的化,那么就可以被采纳(当然如果用上SSD效果估计会更好)。
最后还是想说的是,很多事情是简单做到复杂,复杂再回归到简单,对系统提出的挑战就是如何能够用最直接的方式简单的搞定,而不是做一个臃肿依赖庞大的系统,简单才看的清楚,看的清楚才有机会不断改进。
1 楼 zhufeng1981 2011-10-10 这篇文章见功力,强烈支持。 2 楼 langyu 2011-10-10 这是TOP老大的文章,抄过来也不注明下么?