Hibernate 插入海量数据时的性能 与 Jdbc 的比较
系统环境: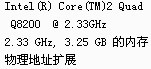
MySQL 数据库环境:
mysql> select version();--------------select version()--------------+----------------------+| version() |+----------------------+| 5.1.41-community-log |+----------------------+1 row in set (0.00 sec)
--launcher.XXMaxPermSize256M-showsplashorg.eclipse.platform--launcher.XXMaxPermSize256m-vmC:/Program Files/Java/jdk1.6.0_18/bin/javaw-vmargs-Dosgi.requiredJavaVersion=1.5-Xms40m-Xmx512m
package com.model;import java.io.Serializable;import java.sql.Timestamp;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import javax.persistence.Table;/** * @author <a href="liu.anxin13@gmail.com">Tony</a> */@Entity@Table(name = "T_USERINFO")@org.hibernate.annotations.Entity(selectBeforeUpdate = true, dynamicInsert = true, dynamicUpdate = true)public class UserInfo implements Serializable {private static final long serialVersionUID = -4855456169220894250L;@Id@Column(name = "ID", length = 32)private String id = java.util.UUID.randomUUID().toString().replaceAll("-", "");@Column(name = "CREATE_TIME", updatable = false)private Timestamp createTime = new Timestamp(System.currentTimeMillis());@Column(name = "UPDATE_TIME", insertable = false)private Timestamp updateTime = new Timestamp(System.currentTimeMillis());// setter/getter...}<?xml version="1.0" encoding="UTF-8"?><beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:tx="http://www.springframework.org/schema/tx"xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-2.5.xsd"><context:component-scan base-package="com.dao,com.service" /><context:property-placeholder location="classpath:jdbc.properties" /><bean id="dataSource" value="${jdbc.driver}" /><property name="jdbcUrl" value="${jdbc.url}" /><property name="user" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /><property name="maxPoolSize" value="50" /><property name="minPoolSize" value="2" /><property name="initialPoolSize" value="5" /><property name="acquireIncrement" value="5" /><property name="maxIdleTime" value="1800" /><property name="idleConnectionTestPeriod" value="1800" /><property name="maxStatements" value="1000"/><property name="breakAfterAcquireFailure" value="true" /><property name="testConnectionOnCheckin" value="true" /><property name="testConnectionOnCheckout" value="false" /></bean><bean id="sessionFactory" ref="dataSource"/><property name="configLocation" value="classpath:hibernate.cfg.xml" /></bean><bean id="hibernateTemplate" ref="sessionFactory" /></bean><bean id="transactionManager" ref="sessionFactory" /></bean><tx:advice id="txAdvice" transaction-manager="transactionManager"><tx:attributes><tx:method name="*" isolation="READ_COMMITTED" rollback-for="Throwable" /></tx:attributes></tx:advice><aop:config><aop:pointcut id="services" expression="execution(* com.service.*.*.*.*(..))" /><aop:advisor advice-ref="txAdvice" pointcut-ref="services" /></aop:config></beans><?xml version='1.0' encoding='UTF-8'?><!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"><hibernate-configuration><session-factory><property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property><!--默认 15, 这是我个人不能完全理解的参数, 不明白这个参数的实际意义--><!-- <property name="hibernate.jdbc.batch_size">50</property> --><!-- 排序插入和更新, 避免出现 锁si --><property name="hibernate.order_inserts">true</property><property name="hibernate.order_updates">true</property><property name="hibernate.hbm2ddl.auto">update</property><property name="hibernate.show_sql">false</property><property name="hibernate.format_sql">false</property><property name="hibernate.current_session_context_class">org.hibernate.context.JTASessionContext</property><mapping /></session-factory></hibernate-configuration>
log4j.rootLogger=INFO, CONSlog4j.appender.CONS=org.apache.log4j.ConsoleAppenderlog4j.appender.CONS.layout=org.apache.log4j.PatternLayoutlog4j.appender.CONS.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss sss} [%p] %r %l [%t] %x - %m%n# log4j.logger.org.springframework=WARN# log4j.logger.org.hibernate=WARN# log4j.logger.com.mchange=WARN package com.dao;import java.io.Serializable;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.orm.hibernate3.HibernateTemplate;@Repositorypublic class HibernateDAO {private static final Logger log = Logger.getLogger(HibernateDAO.class);@Autowiredprivate HibernateTemplate template;public Serializable save(Object entity) {try {return template.save(entity);} catch (Exception e) {log.info("save exception : " + e.getMessage());// 异常的目的只是为了记录日志throw new RuntimeException(e);}}}package com.service;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import com.dao.HibernateDAO;import com.model.UserInfo;@Service("commonService")public class CommonService {private static final Logger log = Logger.getLogger(CommonService.class);@Autowiredprivate HibernateDAO dao;public void testOcean(long num) {for (int i = 0; i < num; i++) {// 在循环中 new 大量对象. 此为 outOfMemory 的根源// 将 user 申明在 循环外面, 循环体内部才将其指向具体的对象, 这样可以提高一点效率UserInfo user = new UserInfo();dao.save(user);user = null;// 实际意义不大, 就算手动运行, gc 也是异步的, 没有办法控制if (i % 100000 == 0)System.gc();/*if (i % 30 == 0) {dao.flush();dao.clear();}*/}}}package com;import org.apache.log4j.Logger;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import com.service.CommonService;@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = { "/applicationContext.xml" })public class TestHibernate {@Autowired@Qualifier("commonService")private CommonService service;private static final Logger log = Logger.getLogger(TestHibernate.class);@Testpublic void testHibernate() {// 海量数据的条数. 分别以 1W, 10W, 50W, 100W 为数值// 虽然都算不上海量, 但做为测试也应该算够了吧long num = 10000;log.info("开始");long begin = System.currentTimeMillis();service.testOcean(num);long end = System.currentTimeMillis();log.info("耗费时间: " + num + " 条. " + (end - begin) / 1000.00000000 + " 秒");System.out.println("赶紧查看内存");try {Thread.sleep(10000);} catch (Exception e) {e.printStackTrace();}}}Hibernate: insert into T_USERINFO (CREATE_TIME, ID) values (?, ?)
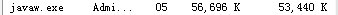




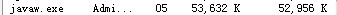
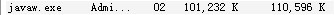

<bean id="jdbcTemplate" ref="dataSource" /></bean>
package com.dao;import java.sql.Connection;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jdbc.core.JdbcTemplate;import org.springframework.stereotype.Repository;@Repositorypublic class JdbcDAO {private static final Logger log = Logger.getLogger(JdbcDAO.class);@Autowiredprivate JdbcTemplate template;public Connection getConn() {try {return template.getDataSource().getConnection();} catch (Exception e) {log.info("获取连接时异常: " + e.getMessage());throw new RuntimeException(e);}}}package com.service;import java.sql.Connection;import java.sql.PreparedStatement;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import com.dao.JdbcDAO;import com.model.UserInfo;@Service("jdbcService")public class JdbcService {private static final Logger log = Logger.getLogger(JdbcService.class);@Autowiredprivate JdbcDAO dao;public void testOcean(long num) {Connection conn = dao.getConn();try {conn.setAutoCommit(false);String sql = "insert into T_USERINFO(CREATE_TIME, ID) values(?, ?)";PreparedStatement pstm = conn.prepareStatement(sql);for (int i = 0; i < num; i++) {// 要保证公平, 也在循环中 new 对象UserInfo user = new UserInfo();pstm.setTimestamp(1, user.getCreateTime());pstm.setString(2, user.getId());pstm.execute();user = null;if (i % 10000 == 0)System.gc();// 批处理/*if (i % 30 == 0) {pstm.executeBatch();conn.commit();pstm.clearBatch();}*/}// 将循环里面的批处理解开后, 就要将此处的commit注释, 并将下面注释的语句解开conn.commit();// pstm.executeBatch();} catch (Exception e) {log.info("异常: " + e.getMessage());} finally {try {conn.close();} catch (Exception e) {conn = null;}}}}package com;import org.apache.log4j.Logger;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import com.service.JdbcService;@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = { "/applicationContext.xml" })public class TestJdbc {private static final Logger log = Logger.getLogger(TestJdbc.class);@Autowired@Qualifier("jdbcService")private JdbcService service;@Testpublic void testJdbc() {long num = 500000;log.info("开始");long begin = System.currentTimeMillis();service.testOcean(num);long end = System.currentTimeMillis();log.info("耗费时间: " + num + " 条. " + (end - begin) / 1000.00000000 + " 秒");System.out.println("赶紧查看内存");try {Thread.sleep(10000);} catch (Exception e) {e.printStackTrace();}}}

for (int i = 0; i < num; i++) {// 要保证公平, 也在循环中 new 对象UserInfo user = new UserInfo();pstm.setTimestamp(1, user.getCreateTime());pstm.setString(2, user.getId());pstm.addBatch();user = null;if (i % 10000 == 0)System.gc();// 批处理if (i % 30 == 0) {pstm.executeBatch();conn.commit();pstm.clearBatch();}}pstm.executeBatch();conn.commit();