Map/Reduce中的Partiotioner使用
一、环境
1、hadoop 0.20.2
2、操作系统Linux
二、背景
1、为何使用Partitioner,主要是想reduce的结果能够根据key再次分类输出到不同的文件夹中。
2、结果能够直观,同时做到对数据结果的简单的统计分析。
三、实现
1、输入的数据文件内容如下(1条数据内容少,1条数据内容超长,3条数据内容正常):
kaka 1 28
hua 0 26
chao 1
tao 1 22
mao 0 29 22
2、目的是为了分别输出结果,正确的结果输出到一个文本,太短的数据输出到一个文本,太长的输出到一个文本,共三个文本输出。
3、代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyPartitioner {
public static class MyPartitionerMap extends Mapper<LongWritable, Text, Text, Text> {
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>.Context context)
throws java.io.IOException, InterruptedException {
String arr_value[] = value.toString().split("\t");
if (arr_value.length > 3) {
context.write(new Text("long"), value);
} else if (arr_value.length < 3) {
context.write(new Text("short"), value);
} else {
context.write(new Text("right"), value);
}
}
}
/**
* partitioner的输入就是map的输出
*
* @author Administrator
*/
public static class MyPartitionerPar extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int numPartitions) {
int result = 0;
if (key.equals("long")) {
result = 0 % numPartitions;
} else if (key.equals("short")) {
result = 1 % numPartitions;
} else if (key.equals("right")) {
result = 2 % numPartitions;
}
return result;
}
}
public static class MyPartitionerReduce extends Reducer<Text, Text, NullWritable, Text> {
protected void reduce(Text key, java.lang.Iterable<Text> value, Context context) throws java.io.IOException,
InterruptedException {
for (Text val : value) {
context.write(NullWritable.get(), val);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: MyPartitioner <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "MyPartitioner");
job.setNumReduceTasks(5);
job.setJarByClass(MyPartitioner.class);
job.setMapperClass(MyPartitionerMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(MyPartitionerPar.class);
job.setReducerClass(MyPartitionerReduce.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、通过key值的不同,对输出的内容切分(切分依据是根据key来做)。虽然设置了5个reduce,但是最终输出的reduce只有3个有内容。截图如下
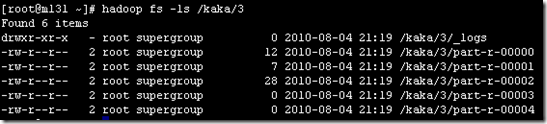
可以看到有3个文本是有值的,其他文本没有值。
四、总结
1、partitioner主要就是为了对结果输出按照key进行分类,在上面的例子中将三种不同的数据分类输出到了三个结果文本中。
2、partitioner输入<k,v>就是map输出的<k,v>
3、需要说明的是,partitioner是将reduce输出做了分区,并不是仅仅是针对输出的文本分区。可以将partitioner中的代码替换为:
return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
4、如果按照代码中的方式来输出,如果判断条件过多,不仅显得代码复杂冗余,而且效率也不高。所以如果是判断条件过多,又不是严格要求
必须每个条件必须输出到一个文件,可以采用上面的方法,输出到一个reduce分区,虽然结果可能是在一个文件中,但是输出是经过排序的。
4、文档写的比较简单,主要是看看实现目标和代码内容,如果有写的不对的地方欢迎发邮件dajuezhao@gmail.com