python 诠释 堆排序
最近在使用java 的PriorityBlockingQueue 发现其排序使用的是堆排序?,于是借这个周末翻了一下大学时候的数据结构的书好好复习了下,堆排序是一种选择排序,堆的定义: n各元素的序列{k1, k2, k3, ……kn},当且仅当满足ki <= k2i ?&& ? ki <= k2i + 1(小顶堆) 或者 ki >= k2i && ki >= k2i+1(大顶堆) 的关系时,称之为堆。
?
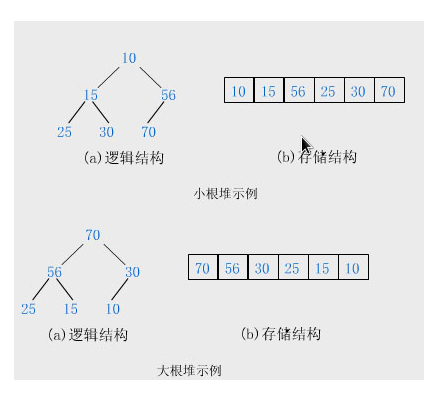
如何构建这样的一个堆呢??
我们现在有这样的一个序列 :
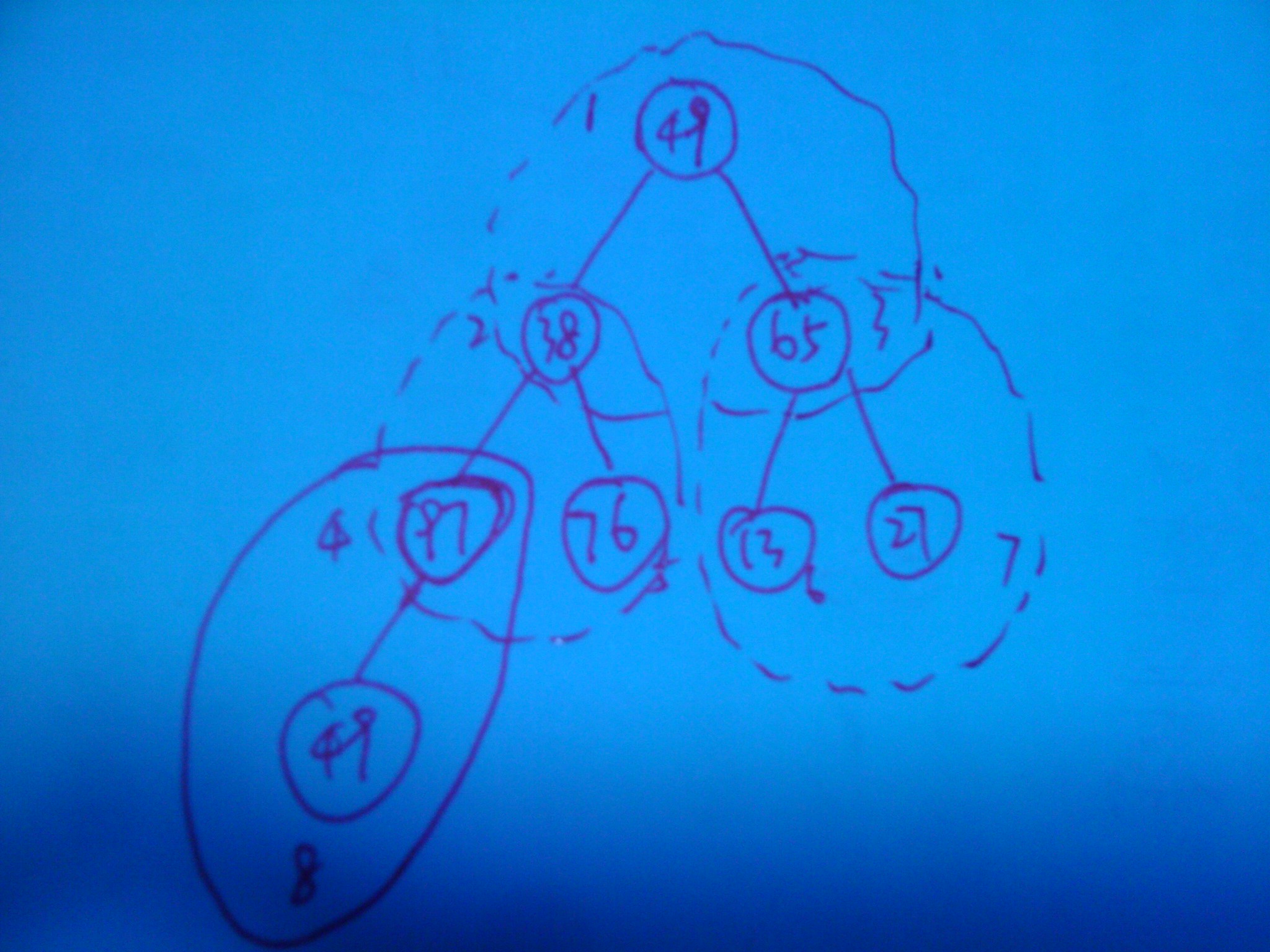
{49,38,65,97,76,13,27,49} ?, 反映成二叉树就是:
?
?
我们可以将此树按非终端结点分成4个部分 , ?按 index 为 4,3 , 2 , 1 的四个顶部节点 自低向上对每个部分按堆的规则进行调整 最后就可以得到一个堆:
?
?
def heap_adjust(list,index): size = len(list) lt = index * 2 rt = index * 2 + 1 largest = index if lt <= size and list[lt-1] >= list[largest-1] : largest = lt if rt <= size and list[rt-1] >= list[largest-1] : largest = rt if largest != index : temp = list[index-1] list[index-1] = list[largest-1] list[largest-1] = temp heap_adjust(list,largest)def build_heap(list): length = len(list) for index in range(length/2,0,-1): heap_adjust(list,index)def heap_pop(list): r = None length = len(list) if length >= 1: r = list[0] if length >= 2: list[0] = list[length-1] list[length-1] = None list.remove(None) heap_adjust(list,1) return rdef heap_append(list,item): list.append(item) build_heap(list) if __name__ == '__main__': list = [49,38,65,97,76,13,27,49] build_heap(list) print list heap_append(list,100) print list length = len(list) for i in range(length): print '%d ' % heap_pop(list),
?
heap_adjust 方法的作用是对每个部分按堆的规则进行调整,在pop 数据时 把第一个数据pop 以后 然后把最后一个数据赋值给第一个?
数据 这样就不会对其余数据的顺序造成影响 只需要对第一个数据进行一次 堆调整就好了……
?
堆排序在记录较少时不值得提倡,但是在大数据量时还是很有效的 ……