前端工程师的编码遭遇战
源码中的meta标签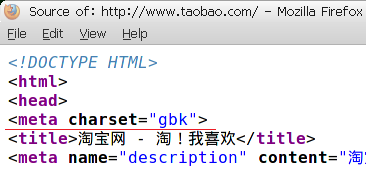
如果三者编码不一致,浏览器会首先读取http头中的content-type,若没有设定编码,再查找页面中meta标签中的charset设定,如果还没有就以浏览器默认编码来显示,如果默认编码没有指定,浏览器会通过解析正文内容来判断编码。所以,页面是gbk编码,即便meta属性中设置charset=utf-8,只要content-type中设定为gbk(或者GB2312、GB18030),该页面就正常显示,如果这时没有设定content-type的编码,浏览器就会以meta中的charset属性为准,页面出现乱码。
在PHP中可以这样设置content-type的编码:header('Content-Type: text/html; charset=GBK');
正确的载入JS文件
html页面载入js文件的时候,需要指定js文件的编码才能正确引用,比如:<script src="gbk.js" charset="gbk" ></script>
可以参照这个demo
JSONP里的中文处理
根据上面的例子,我们知道载入外部JS文件只要指定charset就可以,对JSONP来讲也是如此,但有一个更彻底的杜绝乱码的方法,将JS文件进行unicode编码,这是因为JS引擎的内码是unicode,所以只要是unicode的文本JS都可以识别。就像这样:

PHP中的json_encode函数可以直接将数组作unicode转码。通过JS也可以进行unicode编码,参照这个Demo。
通过JS获取URL
我们注意到,在使用Firefox打开的地址中包含中文时,将其拷贝粘贴到另外的地方却没有得到中文,而是编码后的URL。这是因为浏览器自作聪明的将URL解码为中文来显示的,当我们需要抓取URL的时候需要特别小心,这个Demo在Firefox和IE下打开,JS得到的URL是不一致的。
Firefox:

IE:

如果这个页面不和后台数据发生交互,直接通过document.location.href来取URL是ok的,一旦和后台发生交互,则需要非常小心,最常见出问题的场景是带入登录页的回调地址。比如通过这个地址进入淘宝首页:http://www.taobao.com/?淘宝
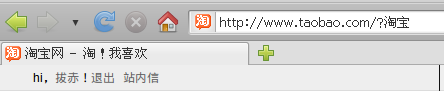
在Firefox和IE下都是可以正常访问的,这时点击吊顶中的“登录”,进入登录页,可以看到在Firefox下的回调地址为:

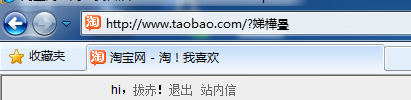
而在IE下的回调地址为:

这时登录淘宝,页面跳转为淘宝首页,可以看到Firefox的地址栏中的URL是正确的,而在IE的地址栏中出现了乱码
Firefox下
IE下
解决办法就是不要用JS去抓取URL写入回调,通过登录页面的Ref或其他方式来抓取。
gbk的页面如何通过JS得到gbk格式的URL编码
我们知道,gbk的页面提交表单是可以作基于gbk的URL编码的,基于这一点,我们可以封装一个函数,实现在gbk页面中使用JS得到gbk格式的URL编码。参照这个Demo,Demo中模拟提交一个表单,然后抓取表单提交的结果,进而得到gbk格式的URL编码。
这样,通过JS就可以控制我希望得到的URL编码了。但在utf-8的页面中是无法实现的。这一点需要尤为注意。