缓存的力量,windows下的slub分配器
上张图先:
该CPU L2=3MB
首先谈谈对象分配池.不管是内存池也好,对象池也好,首要的速度就是要快。可能有人说内存池为了碎片问题,那减轻碎片负担是不是也是为了速度快呢? 影响速度首先要从2个角度考虑,一个是机器的硬件特性,其次是缓存的命中率。硬件特性包括了对各种不同大小字段的读取,而缓存命中率在大内存的时候更显得犹为重要(因为内存没有硬盘的I/O瓶颈一说)。一会会结合数据图一一指出。所以在写的时候,为slub提供了以下特性:(多参考自linux源码,精练而成)
1.以页面为颗粒度,进行分配。
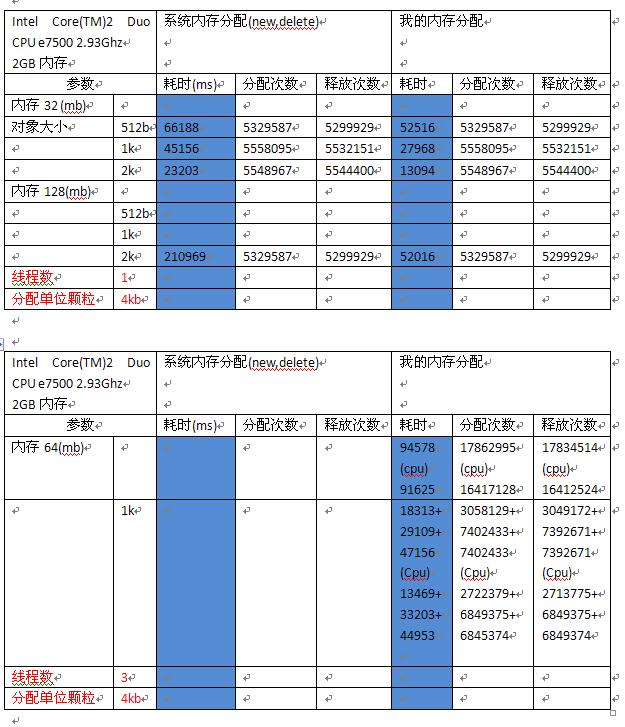
比如32机器上的页面为4KB,则每次分配以4KB做为颗粒度。当然这个可以调节,以支持大于一个页面的对象。
2.尽量从回收的页面中分配,以保持缓存命中率。并且维持这种顺序,不被分配打乱
比如一个页面分为100个对象,释放了10个对象,那么下次分配时,尽量从释放的10个中申请。而常见的链表式池,在使用次数多后,最影响的性能方面就是1号对象指向了最末尾等等
3.缓存的回收
虽然在服务器上内存的政策是鸵鸟式,这也是我以前的观点。但是现在的想法还是如果能做到一款动态伸缩,并且不影响效率,实在是快哉。不过在该代码里面,回收暂时不是重点,在回收的时候我也仅仅以vector遍历查找。一般不开
4.坏区的检测
对每个内存块分配特定的值,检测是否坏,或者不对的内存.可以屏蔽
5.多核的缓存支持
这里多核不是指多线程的支持。当然,它支持多线程并发。这里指的是利用多核建立的缓存结构。写之前对它将信将疑,不知道性能能提高多少,测试后也确实如此,性能提高得可怜。但也可能鉴于机器情况(双核),如果在忙碌的多核下,我相信性能还是有多提升的。
分析数据得出来的经验:
补充下测试环境,图里没写全:windows xp sp2+32位CPU
测试的时候, 网页等操作正常,myslub中所有检测全关
没有测试所有的数据,一是平常中已经测过,但没有记录,发上来总得象样点;二是心里大概有个样本了,没有花费太多时间做这事
我的测试方式:
?
?
S32 __CMYMalloc::Run(){DWORD t1 = GetTickCount();while(g_bQuit==false && InterlockedDecrement(&m_nCount)+1 ){int i, nRand;//申请nRand = Random(0, name_viralloc::SUM_ALLOC_BYTE/m_nObjectSize-Vector.size());for(i=0; i<nRand; ++i){void *p = m_Kmem.KmemMalloc();if(NULL==p){break;}*(int*)p = 1000;Vector.push_back(p);++m_nMalloc;}//释放nRand = Random(0, Vector.size());for(i=0; i<nRand; ++i){int j = Random(0, Vector.size());if( NULL==Vector[j] ){continue;}m_Kmem.KmemFree(Vector[j]);Vector.erase(Vector.begin()+j);++m_nFree;}}printf("spend:%d\n", GetTickCount()-t1);return 0;Vector,事先进行了reserve,?name_viralloc::SUM_ALLOC_BYTE/m_nObjectSize计算出能分配的所有对象数。也就是说,一个单位的测试
动作包括了,随机分配内存,再计算出一个随机释放内存的数,并且对每个释放的索引再次随机。那么进行几次这样的单位测试成为一个很重要的指数。理想的值应该是跟能分配的所有对象数进行一个比例进行,我在测试中一般设为500-1000,并且以KB为单位。(如果是byte为单位,速度慢得重启,十几,二十分钟的计算)虽然有点偏颇,但还是可以做为一个样本参考。
总结出的一些内存经验:
单线程:
1.一次性分配2个页面做为一个单位颗粒,可以提高速度吗?证明不能,甚至还有拖慢的嫌疑。在32位机器下
2.在分配次数差不多的情况下,对象体积大的速度反而比小的快了很多。不得其解。后来和同事一致认为,就好比读取int i; char c,后者耗费的时间肯定比前者多一个指令
?
3.同样是2k的对象大小,在内存从32->128的情况下,系统的耗时差了10倍,我的差了4倍。进一步说明在大内存下,缓存不连续下的性能最大耗费
?
4.在128MB,我没有测试1k(太慢了)。但是我敢肯定跟32mb的差值远远小于2k的10倍。很简单原理如下:在系统进行分配内存时,都会或多或少的加入一些字段进行校验或者记录信息。如果你的大小是2K,那么对齐后的大小必然是>2k,如果系统的页面颗粒不进行调整,就会造成极大的浪费。所以你的对象分配时在32机器上跟4KB的页面对齐有问题,就要小心了。
?
多线程下:
5.尝试了下开多核的缓存设置(实现见代码,很简单的技巧)。在单线程下,反而显得慢。这个道理很简单,单个线程的忙碌,切到另外个CPU非常偶然。比如10次的0号CPU,1次的1号CPU。切的缓存命中不大,反而还要0号再次反切。在多线程下虽然有提升,但是少得可怜。由于硬件条件,没有再进行4核,8核的测试。
两个额外的想法:
1.C的链表 VS STL
先来推一个论点:
STL中只是对链表对象的一个包装,因为对用户是透明的,所以给用户展示的还是原来的结构。那么就意味着,链表信息无法原来的结构体中取得,如果要进行增,删,改,则必须进行查询找到链表节点
假设有结构
struct page
{
list head; //如果是C,以linux下的链表使用方法为代表,直接将信息作为结构体的一个成员变量
};
接着将page串成链表
C中,list_add_tail(). C中是以数据结构和操作方法分开,典型的过程式写法
C++中,list<page*> List; List.push(); 类的思维写法,一个对象包括代码和数据
当我要进行删除的时候
void *p; //我的内存地址
pPage = virt_to_head_page(p); //反算出page
C中,list_del(pPage);//直接删除,因为本身就有结点信息
C++中,List.删除(pPage); //我的做法是,先find到itr,然后erase.如果是remove,好象是一个遍历
2. 执行序列的优化
int i = 40;
int j = 100;
i = 20;
j = i;
i = 30;
那么在执行j=i的时候,能不能探测到下一条语句是i,可以事先缓存住i的地址,然后就可以直接执行i=30这条语句.那么在INTEL CPU中使用的技术是乱序。但找了几天资料也没搞明白怎么防止不乱序(即j=i先于i=30执行)。这样的话就可以衍生到应用层对象处理上优化。比如有1,10, 2玩家发来指令,先放在指令池里(cpu架构也是这么干的)但是可知1,2号在同一个页上,于是就可以先处理1,2玩家的命令。
?
1 楼 lin_style 2010-07-14 草。居然还有SB踩我。留下意见来