浅谈字符编码(三)- 乱码的产生与解决
仅供参考...
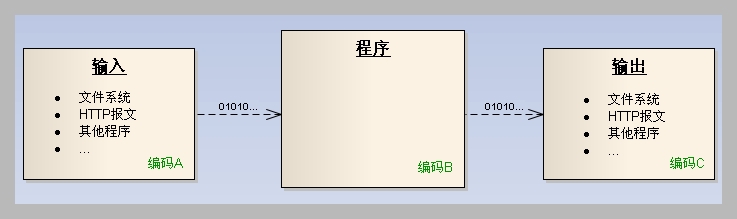
一个程序的基本特征就是输入输出,而乱码的产生也基本上发生在这两个阶段
例如一个程序的输入,无论是来自文件,数据库,网络传送来的相关协议报文,或是其他程序发送来的消息等等,它们都是以某种编码格式(假设编码A)的字节序列进行存储传输的,当程序接收到这些以编码A进行编码的字节序列时,由于程序本身运行时使用某种默认的字符编码格式(例如JAVA中char是以Unicode字符存储的。这里假设为编码B),所以如果此时程序不对两者统一就进行交互处理的话,可以想象会发生什么?在编码B的码表里根据编码A提供的索引查找会出现什么?如果编码A是单字节编码,编码B却是双字节编码又会发生什么?乱码由此产生。输出时情况也类似。
上面说的是程序运行阶段,乱码还会出现的一个地方则是程序从源代码到目标代码的阶段,其实同上面一样,只是输入换成了源代码(由TXT或其他文本编辑器或IDE以某种编码格式存储为源文件格式),而程序则换做了编译器程序,输出则变成了目标代码(.obj或.class等)
Tomcat中servlet编程中文乱码解决办法:
在servlet编程中,由于tomcat服务器中默认使用iso8859-1的编码表,如果请求或响应中包含中文字符:
・对于get方式:
byte[] b1 = s1.getBytes("iso8859-1");
String s2 = new String(b1, "gbk");
System.out.println(s2);
或者更简单的修改server.xml :
<Connector port="80" protocol"HTTP/1.1" ... URIEncoding="GBK"/>
・对于post方式:
request.setCharacterEncoding("GBK");//注意写在取参数前
・响应:
resp.setContentType("text/html;charset=gbk");//注意写在PrintWriter out = resp.getWriter()之前
操作系统的默认编码方式:
通常编辑器程序在读取和保存源代码文件的时候,默认采用的都是操作系统的默认编码方式,在Java中可通过如下方式查询:
System.out.println(System.getProperty("file.encoding"));
编译时指定源代码编码方式:
例如在Java中,使用-encoding参数指定,如果没有用-encoding参数指定我们的JAVA源程序的编码格式,则javac.exe会默认使用操作系统默认的编码格式(中文的操作系统一般都是GBK)