StanfordЛњЦїбЇЯА---ЕкЮхНВ. ЩёОЭјТчЕФбЇЯА Neural Networks learning
БОРИФПЃЈMachine learningЃЉАќРЈЕЅВЮЪ§ЕФЯпадЛиЙщЁЂЖрВЮЪ§ЕФЯпадЛиЙщЁЂOctave TutorialЁЂLogistic RegressionЁЂRegularizationЁЂЩёОЭјТчЁЂЛњЦїбЇЯАЯЕЭГЩшМЦЁЂSVMЃЈSupport Vector Machines жЇГжЯђСПЛњЃЉЁЂОлРрЁЂНЕЮЌЁЂвьГЃМьВтЁЂДѓЙцФЃЛњЦїбЇЯАЕШеТНкЁЃЫљгаФкШнОљРДздStandfordЙЋПЊПЮmachine learningжаAndrewРЯЪІЕФНВНтЁЃЃЈhttps://class.coursera.org/ml/class/indexЃЉ
ЕкЮхНВЁЊЁЊNeural Networks ЩёОЭјТчЕФБэЪО
===============================
Cost function
Backpropagation algorithm
Backpropagation intuition
Implementation note: Unrolling parameters
Gradient checking
Random initialization
Putting it together
===============================
Cost function
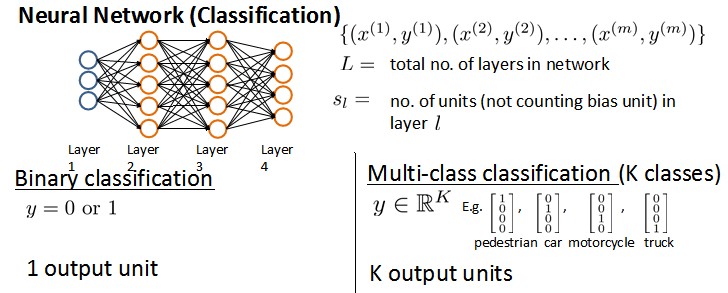
МйЩшЩёОЭјТчЕФбЕСЗбљБОгаmИіЃЌУПИіАќКЌвЛзщЪфШыxКЭвЛзщЪфГіаХКХyЃЌLБэЪОЩёОЭјТчВуЪ§ЃЌSlБэЪОУПВуЕФneuronИіЪ§(SLБэЪОЪфГіВуЩёОдЊИіЪ§)ЁЃ
НЋЩёОЭјТчЕФЗжРрЖЈвхЮЊСНжжЧщПіЃКЖўРрЗжРрКЭЖрРрЗжРрЃЌ
eЖўРрЗжРрЃКSL=1, y=0 or 1БэЪОФФвЛРрЃЛ
eKРрЗжРрЃКSL=K, yi = 1БэЪОЗжЕНЕкiРрЃЛЃЈK>2ЃЉ
ЮвУЧдкЧАМИеТжавбОжЊЕРЃЌLogistic hypothesisЕФCost FunctionШчЯТЖЈвхЃК
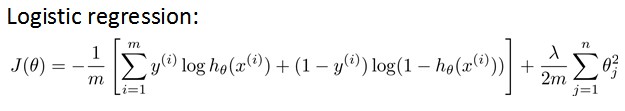
ЦфжаЃЌЧААыВПЗжБэЪОhypothesisгыецЪЕ值жЎМфЕФОрРыЃЌКѓАыВПЗжЮЊЖдВЮЪ§НјааregularizationЕФbiasЯюЃЌЩёОЭјТчЕФcost functionЭЌРэЃК
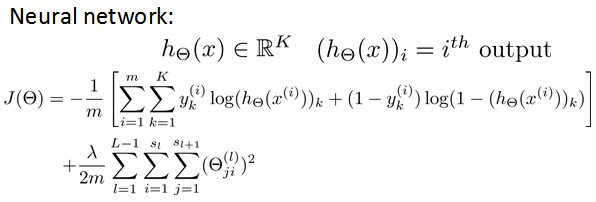
hypothesisгыецЪЕ值жЎМфЕФОрРыЮЊ УПИібљБО-УПИіРрЪфГі ЕФМгКЭЃЌЖдВЮЪ§НјааregularizationЕФbiasЯюДІРэЫљгаВЮЪ§ЕФЦНЗНКЭ
===============================
Backpropagation algorithm
ЧАУцЮвУЧвбОНВСЫcost functionЕФаЮЪНЃЌЯТУцЮвУЧашвЊЕФОЭЪЧзюаЁЛЏJ(ІЈ)

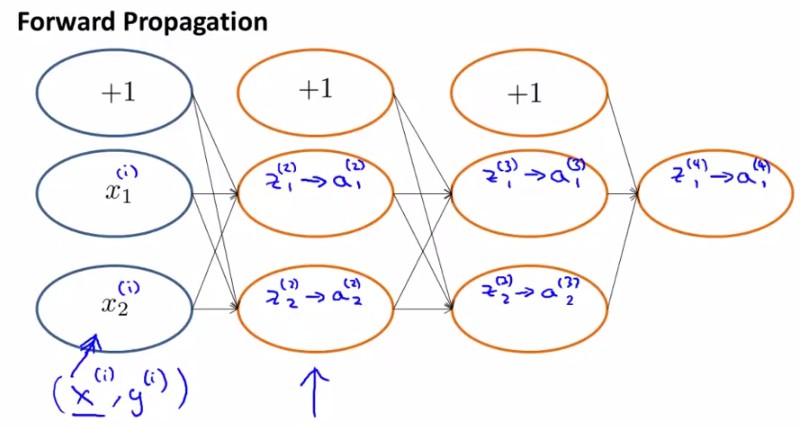
ЯывЊИљОнgradient descentЕФЗНЗЈНјааВЮЪ§optimizationЃЌЪзЯШашвЊЕУЕНcost functionКЭвЛаЉВЮЪ§ЕФБэЪОЁЃИљОнforward propagation,ЮвУЧЪзЯШНјааtraining dataset дкЩёОЭјТчЩЯЕФИїВуЪфГі值ЃК
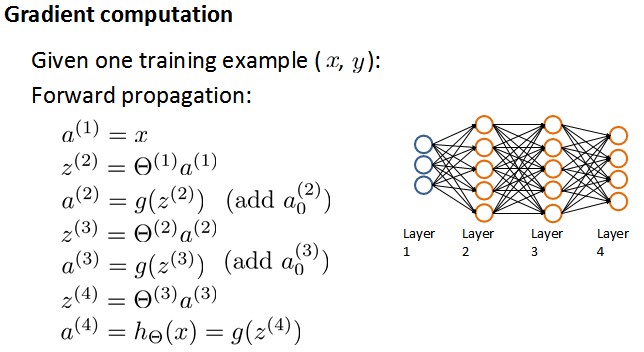
ШЛКѓИљОнbackpropagationЫуЗЈНјааЬнЖШЕФМЦЫуЃЌетРяв§ШыСЫerrorБфСПІФЃЌгУРДБэЪОецЪЕ值гыforward propagationМЦЫу值жЎМфЕФВюЃЌвВЪЧЬнЖШЕФжївЊвРОнРДдДЁЃ
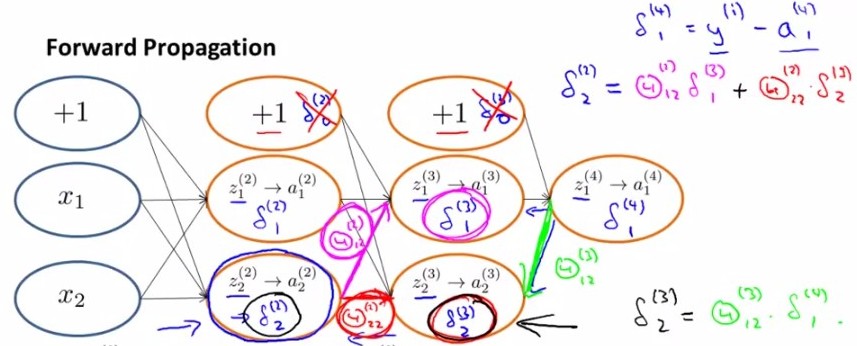
МйЩшвЛИіЙВга4ВуЕФЩёОЭјТчЃЌдкзюКѓвЛВуЃЌІФ(4)= a(4)-yЃЌЖјЧАУцУПвЛВуЕФІФ(j)гЩКѓвЛВуДЋЙ§РДЕФІФ(j+1)гыЩЯвЛВуВЮЪ§ЕФЛ§КЭg'(z(j))ЕФЕуЛ§ОіЖЈЃЈЙЋЪНМћЯТЭМЃЉЁЃЖдгкЙЋЪН
ІФ(j)=(ІЈ(j))TІФ(j+1) .* g'(z(j))
g'(z(j))=a(j).*(1-a(j)),
Цфжа z(j)КЭa(j)ЖМЪЧСаЯђСПЃЌ1БэЪОвЛСа1ЯђСПЁЃ

гЩЩЯЭМЮвУЧЕУЕНСЫerrorБфСПІФЕФМЦЫуЃЌЯТУцЮвУЧРДПДbackpropagationЫуЗЈЕФЮБДњТыЃК

psЃКзюКѓвЛВНжЎЫљвдаД+=ЖјЗЧжБНгИГ值ЪЧАбІЄПДзіСЫвЛИіОиеѓЃЌУПДЮдкЯргІЮЛжУЩЯзіаоИФЁЃ
ДгКѓЯђЧАДЫМЦЫуУПВувРЕФІФЃЌгУІЄБэЪОШЋОжЮѓВюЃЌУПвЛВуЖМЖдгІвЛИіІЄ(l)ЁЃдйв§ШыDзїЮЊcost functionЖдВЮЪ§ЕФЧѓЕМНсЙћЁЃЯТЭМзѓБпjЪЧЗёЕШгк0гАЯьЕФЪЧЪЧЗёгазюКѓЕФbias regularizationЯюЁЃзѓБпЪЧЖЈвхЃЌгвБпПЩжЄУїЃЈБШНЯЗБЫіЃЉЁЃ

===============================
Backpropagation intuition
ЩЯУцНВСЫbackpropagationЫуЗЈЕФВНжшвдМАвЛаЉЙЋЪНЃЌдкетвЛаЁНкжаЮвУЧНВвЛЯТзюМђЕЅЕФback-propagationФЃаЭЪЧдѕбљlearningЕФЁЃЪзЯШИљОнforward propagationЗНЗЈДгЧАЭљКѓМЦЫуz(j),a(j) ;
ШЛКѓНЋдcost function НјааМђЛЏЃЌШЅЕєЯТЭМжаКѓУцФЧЯюregularizationЯюЃЌ
ФЧУДЖдгкЪфШыЕФЕкiИібљБО(xi,yi)ЃЌга
Cost(i)=y(i)log(hІШ(x(i)))+(1- y(i))log(1- hІШ(x(i)))
ФЧУДЖдгкerrorЗжСПЃЌга
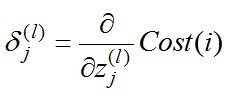
ОЙ§ЧѓЕММЦЫуПЩЕУЃЌЖдгкЩЯЭМга
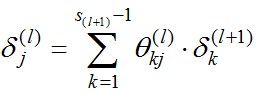
ЛЛОфЛАЫЕ, ЖдгкУПвЛВуРДЫЕЃЌІФЗжСПЖМЕШгкКѓУцвЛВуЫљгаЕФІФМгШЈКЭЃЌЦфжаШЈ值ОЭЪЧВЮЪ§ІЈЁЃ
===============================
Implementation note: Unrolling parameters
етвЛНкНВЪіmatlabжаШчКЮЪЕЯжunrolling parameterЁЃ
ЧАМИеТжавбОНВЙ§дкmatlabжаРћгУЬнЖШЯТНЕЗНЗЈНјааИќаТЕФИљБОЃЌСНИіЗНГЬЃК
function [jVal, gradient] = costFunction(theta)optTheta = fminunc(@costFunction, initialTheta, options)гыlinear regressionКЭlogistic regressionВЛЭЌЃЌдкЩёОЭјТчжаЃЌВЮЪ§ЗЧГЃЖрЃЌУПвЛВуjгавЛИіВЮЪ§ЯђСПІЈjКЭDerivativeЯђСПDjЁЃФЧУДЮвУЧЪзЯШНЋИїВуЯђСПСЌЦ№РДЃЌзщГЩДѓvectorІЈКЭDЃЌДЋШыfunctionЃЌдйдкМЦЫужаНјааЯТЭМжаЕФreshapeЃЌЗжБ№ШЁГіНјааМЦЫуЁЃ

МЦЫуЪБЃЌЗНЗЈШчЯТЃК

===============================
Gradient checking
ЩёОЭјТчжаМЦЫуЦ№РДЪ§зжЧЇБфЭђЛЏФбвдеЦЮеЃЌФЧЮвУЧдѕУДжЊЕРЫќРяЭЗЙЄзїЕФЖдВЛЖдФиЃПВЛХТЃЌЮвУЧгаЗЈБІЃЌОЭЪЧgradient checkingЃЌЭЈЙ§checkЬнЖШХаЖЯЮвУЧЕФcodeгаУЛгаЮЪЬтЃЌokЃПдѕУДзіФиЃЌПДЯТБпЃК
ЖдгкЯТУцетИіЁОІЈ-J(ІЈ)ЁПЭМЃЌШЁІЈЕузѓгвИївЛЕуЃЈІЈ+ІХЃЉЃЌЃЈІЈ-ІХЃЉЃЌдђгаЕуІЈЕФЕМЪ§ЃЈЬнЖШЃЉНќ似ЕШгк(JЃЈІЈ+ІХЃЉ-JЃЈІЈ-ІХЃЉ)/(2ІХ)ЁЃ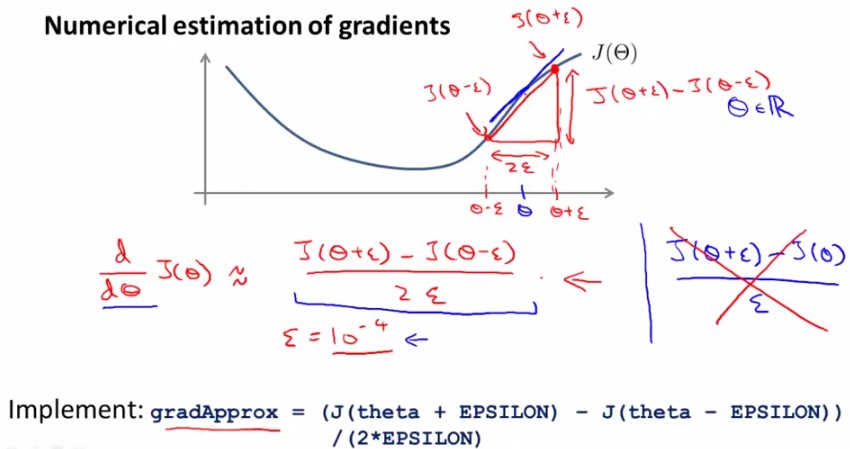
ЖдгкУПИіВЮЪ§ЕФЧѓЕМЙЋЪНШчЯТЭМЫљЪОЃК

гЩгкдкback-propagationЫуЗЈжаЮвУЧвЛжБФмЕУЕНJ(ІЈ)ЕФЕМЪ§DЃЈderivativeЃЉЃЌФЧУДОЭПЩвдНЋетИіНќ似值гыDНјааБШНЯЃЌШчЙћетСНИіНсЙћЯрНќОЭЫЕУїcodeе§ШЗЃЌЗёдђДэЮѓЃЌШчЯТЭМЫљЪОЃК

Summary: гавдЯТМИЕуашвЊзЂвт
-дкback propagationжаМЦЫуГіJ(ІШ)ЖдІШЕФЕМЪ§DЃЌВЂзщГЩvectorЃЈDvecЃЉ
-гУnumerical gradient checkЗНЗЈМЦЫуДѓИХЕФЬнЖШgradApprox=(JЃЈІЈ+ІХЃЉ-JЃЈІЈ-ІХЃЉ)/(2ІХ)
-ПДЪЧЗёЕУЕНЯрЭЌЃЈorЯрНќЃЉЕФНсЙћ
-ЃЈетвЛЕуЗЧГЃживЊЃЉЭЃжЙcheckЃЌжЛгУback propagation РДНјааЩёОЭјТчбЇЯАЃЈЗёдђЛсЗЧГЃТ§ЃЌЯрЕБТ§ЃЉ

===============================
Random Initialization
ЖдгкВЮЪ§ІШЕФinitializationЮЪЬтЃЌЮвУЧжЎЧАВЩгУШЋВПИГ0ЕФЗНЗЈЃЌБШШчЃК
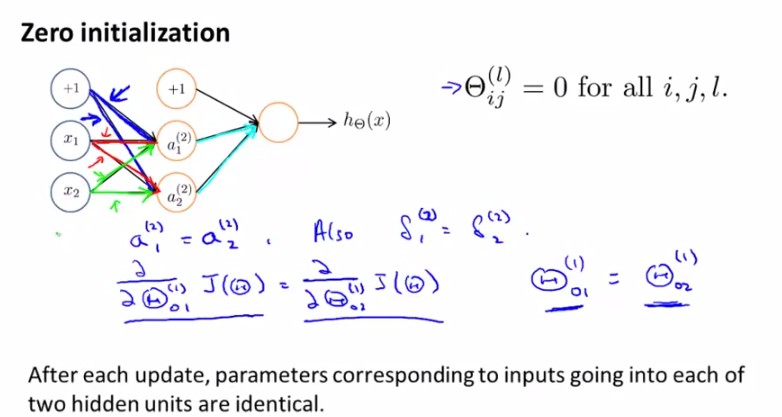
ЫљвдЮвУЧгІИУДђЦЦетжжsymmetryЃЌrandomlyбЁШЁУПвЛИіparameterЃЌдк[-ІХ,ІХ]ЗЖЮЇФкЃК

===============================
Putting it together
1. бЁдёЩёОЭјТчНсЙЙ
ЮвУЧгаКмЖрchoices of network :
ФЧУДдѕУДбЁдёФиЃП
No. of input units: Dimension of features
No. output units: Number of classes
Reasonable default: 1 hidden layer, or if >1 hidden layer, have same no. of hidden units in every layer (usually the more the better)
2. ЩёОЭјТчЕФбЕСЗ
Ђй Randomly initialize weights
Ђк Implement forward propagation to get hІШ(x(i)) for any x(i)
Ђл Implement code to compute cost function J(ІШ)
Ђм Implement backprop to compute partial derivatives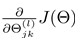

Ђн

Ђо

test:

БОеТНВЪіСЫЩёОЭјТчбЇЯАЕФЙ§ГЬЃЌжиЕудкгкback-propagationЫуЗЈЃЌgradient-checkingЗНЗЈЃЌЯЃЭћФмЙЛгаШЫгУЮвжЎЧАетЦЊЮФеТжаЕФРр似ЗНЗЈгшвдЪЕЯжЩёОЭјТчЁЃ
ЙигкMachine LearningИќЖрЕФбЇЯАзЪСЯНЋМЬајИќаТЃЌОДЧыЙизЂБОВЉПЭКЭаТРЫЮЂВЉSophia_qingЁЃ