ORACLE 索引原理
(本文内容均整理自万能的INTERNET)
B-TREE索引
一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
?????? 当发出where c1='01'这样的SQL语句时,oracle会去搜索01所在的索引条目,然后扫描该索引条目中的bitmap里所有的bit位。第一个bit位为1,则说明第一条记录上的C1值为01,于是返回第一条记录所在的ROWID(根据该索引条目里记录的start ROWID加上行号得到该记录所在的ROWID)。第二个bit位为0,则说明第二条记录上的C1值不为01,依此类推。另外,如果索引列为空,也会在位图索引里记录,也就是将对应的bit位设置为0即可。
?????? 如果索引列上不同值的个数比较少的时候,比如对于性别列(男或女)等,则使用位图索引会比较好,因为它对空间的占用非常少(因为都是用bit位来表示表里的数据行),从而在扫描索引的时候,扫描的索引块的个数也比较少。可以试想一下,如果在列的不同值非常多的列上,比如主键列上,创建位图索引,则产生的索引条目就等于表里记录的条数,同时每个索引条目里的bitmap里,只有一个1,其它都是0。这样还不如B树索引的效率高。
如果被索引的列经常被更新的话,则不适合使用位图索引。因为当更新位图所在的列时,由于要在不同的索引条目之间修改bit位,比如将第一条记录从01变为02,则必须将01所在的索引条目的第一个bit位改为0,再将02所在的索引条目的第一个bit位改为1。因此,在更新索引条目的过程中,会锁定位图索引里多个索引条目。也就是同时只能有一个用户能够更新表T,从而降低了并发性。
位图索引比较适合用在数据仓库系统里,不适合用在OLTP系统里。
?
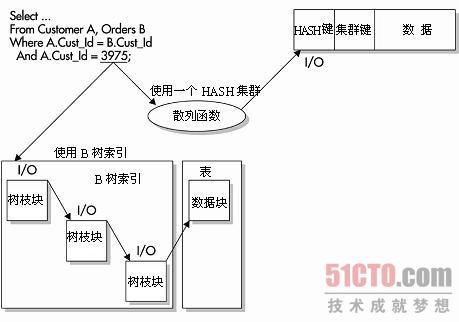
HASH索引????? 使用HASH索引必须要使用HASH集群。建立一个集群或HASH集群的同时,也就定义了一个集群键。这个键告诉Oracle如何在集群上存储表。在存储数据时,所有与这个集群键相关的行都被存储在一个数据库块上。如果数据都存储在同一个数据库块上,并且将HASH索引作为WHERE子句中的确切匹配,Oracle就可以通过执行一个HASH函数和I/O来访问数据-- 而通过使用一个二元高度为4的B树索引来访问数据,则需要在检索数据时使用4个I/O。如图2-5所示,其中的查询是一个等价查询,用于匹配HASH列和确切的值。Oracle可以快速使用该值,基于HASH函数确定行的物理存储位置。
????? HASH索引可能是访问数据库中数据的最快方法,但它也有自身的缺点。集群键上不同值的数目必须在创建HASH集群之前就要知道。需要在创建HASH集群的时候指定这个值。低估了集群键的不同值的数字可能会造成集群的冲突(两个集群的键值拥有相同的HASH值)。这种冲突是非常消耗资源的。冲突会造成用来存储额外行的缓冲溢出,然后造成额外的I/O。如果不同HASH值的数目已经被低估,您就必须在重建这个集群之后改变这个值。ALTER CLUSTER命令不能改变HASH键的数目。
????? HASH集群还可能浪费空间。如果无法确定需要多少空间来维护某个集群键上的所有行,就可能造成空间的浪费。如果不能为集群的未来增长分配好附加的空间,HASH集群可能就不是最好的选择。
如果应用程序经常在集群表上进行全表扫描,HASH集群可能也不是最好的选择。由于需要为未来的增长分配好集群的剩余空间量,全表扫描可能非常消耗资源。
?
在实现HASH集群之前一定要小心。您需要全面地观察应用程序,保证在实现这个选项之前已经了解关于表和数据的大量信息。通常,HASH对于一些包含有序值的静态数据非常有效。
技巧:
HASH索引在有限制条件(需要指定一个确定的值而不是一个值范围)的情况下非常有用。
?
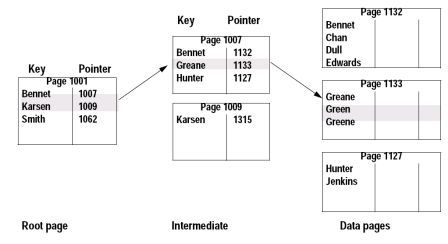
聚族索引????? 在这里还是用字典来进行类比,一般来说汉语字典中有几种索引,如拼音、偏旁、笔画等。字典本身的组织也是排序的,我记得一般是按照拼音排序的。这里的拼音就是聚族索引。也就是说聚族索引的组织顺序和数据本身的组织顺序是一致的 ,这也解释了数据库中只能定义一个聚族索引的原因,因为数据本身只能按一种方式进行排序。
????? 那聚族索引有什么特别的好处呢,这个好处就是在数据库中执行查找一批数据的语句会比较快,因为数据已经按照聚族索引排好序了,很少的io操作就可以将数据从库中取出。好比你在字典中查找发音从从a到c的汉字,只需要查到a的开始页和c的结束页,中间的所有页都符合查询要求,不用再一页一页地查找。
?
?
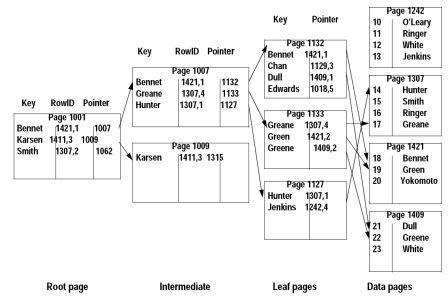
非聚族索引????? 非聚族索引就好比字典里的偏旁、笔画索引,其 索引组织顺序和数据组织顺序不一致 ,因此非聚族索引可以创建多个。当查找一条数据时,非聚族索引和聚族索引的效率相差不大,但查找一批数据(n)时,非聚族索引需要的io可能是聚族索引的n倍,因为非聚族索引需要一条一条地进行查找。
?
?