Hadoop集群上使用Lzo压缩
我们配置Hadoop默认的Block大小是128M,如果我们想切分成更多的Map任务,可以通过设置其最大的SplitSize来完成:
FileInputFormat.setMaxInputSplitSize(job, 64 *1024 * 1024);
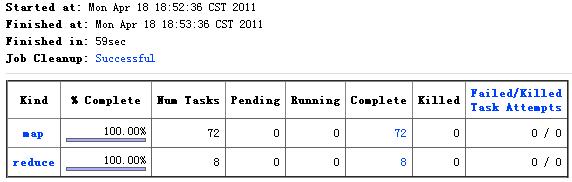
最终,12个文件被切分成了72个Map来处理,但处理时间反而长了,为59s,如下图:
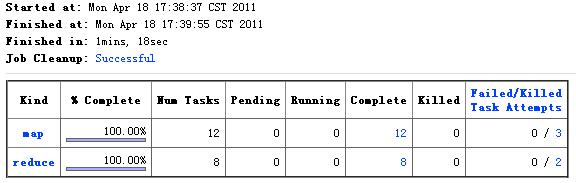
而对于Gzip压缩的文件,即使我们设置了setMaxInputSplitSize,最终的Map数仍然是输入文件的数目12,执行时间为78s,如下图:
从以上的简单测试可以看出,使用Lzo压缩,性能确实比Gzip压缩要好不少
?
==============================================================
HBase的性能优化和相关测试
?
HBase的写效率还是很高的,但其随机读取效率并不高
可以采取一些优化措施来提高其性能,如:
1. 启用lzo压缩,见这里
2. 增大hbase.regionserver.handler.count数为100
3. 增大hfile.block.cache.size为0.4,提高cache大小
4. 增大hbase.hstore.blockingStoreFiles为15
5. 启用BloomFilter,在HBase0,89中可以设置
6.Put时可以设置setAutoFlush为false,到一定数目后再flushCommits
?
在14个Region Server的集群上,新建立一个lzo压缩表
测试的Put和Get的性能如下:
1. Put数据:
单线程灌入1.4亿数据,共花费50分钟,每秒能达到4万个,这个性能确实很好了,不过插入的value比较小,只有不到几十个字节
多线程put,没有测试,因为单线程的效率已经相当高了
2. Get数据:
在没有任何Block Cache,而且是Random Read的情况:
单线程平均每秒只能到250个左右
6个线程平均每秒能达到1100个左右
16个线程平均每秒能达到2500个左右
有BlockCache(曾经get过对应的row,而且还在cache中)的情况:
单线程平均每秒能到3600个左右
6个线程平均每秒能达到1.2万个左右
16个线程平均每秒能达到2.5万个左右