探索 Linux 内存模型
理解 Linux 使用的内存模型是从更大程度上掌握 Linux 设计和实现的第一步,因此本文将概述 Linux 内存模型和管理。
Linux 使用的是单一整体式结构 (Monolithic),其中定义了一组原语或系统调用以实现操作系统的服务,例如在几个模块中以超级模式运行的进程管理、并发控制和内存管理服务。尽管出于兼容性考虑,Linux 依然将段控制单元模型 (segment control unit model)?保持一种符号表示,但实际上已经很少使用这种模型了。
与内存管理有关的主要问题有:
本文探讨了以下问题,可以帮助您从操作系统中内存管理的角度来理解 Linux 的内幕:
虽然本文并没有详细介绍 Linux 内核管理内存的方法,但是介绍了有关整个内存模型的知识以及系统的寻址方式,这些介绍可为您进一步的学习提供一个框架。本文重点介绍的是 x86 架构,但本文中的知识对于其他硬件实现同样适用。
?
下面让我们来介绍一下段控制单元模型。
?
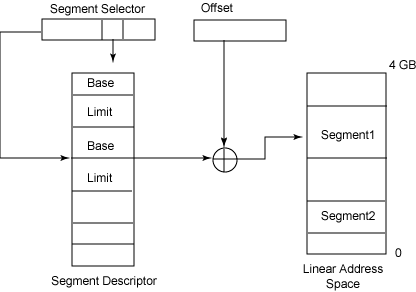
每次将段选择器加载到段寄存器中时,对应的段描述符都会从内存加载到相匹配的不可编程 CPU 寄存器中。每个段描述符长 8 个字节,表示内存中的一个段。这些都存储到 LDT 或 GDT 中。段描述符条目中包含一个指针和一个 20 位的值(Limit 字段),前者指向由 Base 字段表示的相关段中的第一个字节,后者表示内存中段的大小。
其他某些字段还包含一些特殊属性,例如优先级和段的类型(cs?或?ds)。段的类型是由一个 4 位的 Type 字段表示的。
由于我们使用了不可编程寄存器,因此在将逻辑地址转换成线性地址时不引用 GDT 或 LDT。这样可以加快内存地址的转换速度。
段选择器包含以下内容:
由于一个段描述符的大小是 8 个字节,因此它在 GDT 或 LDT 中的相对地址可以这样计算:段选择器的高 13 位乘以 8。例如,如果 GDT 存储在地址 0x00020000 处,而段选择器的 Index 域是 2,那么对应的段描述符的地址就等于 (2*8) + 0x00020000。GDT 中可以存储的段描述符的总数等于 (2^13 - 1),即 8191。
图 3 展示了从逻辑地址获得线性地址。
 ?
?那么这在 Linux 环境下有什么不同呢?
?
![]()
![]()
回页首
?
注意,上图 Page1 中包含的地址集正好与 Page Frame1 中包含的地址集匹配。
在 Linux 中,分页单元的使用多于分段单元。前面介绍 Linux 分段模型时已提到,每个分段描述符都使用相同的地址集进行线性寻址,从而尽可能降低使用分段单元将逻辑地址转换成线性地址的需要。通过更多地使用分页单元而非分段单元,Linux 可以极大地促进内存管理及其在不同硬件平台之间的可移植性。
?
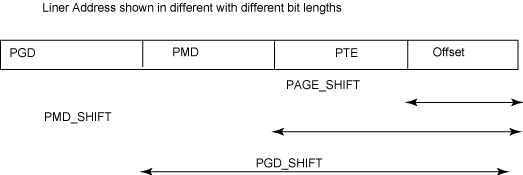
开始时,首先将页目录的物理地址加载到?cr3?寄存器中。线性地址中的 Directory 字段确定页目录中指向恰当的页表条目。Table 字段中的地址确定包含页的页框物理地址所在页表中的条目。Offset 字段确定了页框中的相对位置。由于 Offset 字段为 12 位,因此每个页中都包含有 4 KB 数据。
下面小结物理地址的计算:
cr3?+ Page Directory (10 MSB) = 指向?table_basetable_base?+ Page Table (10 中间位) = 指向?page_basepage_base?+ Offset = 物理地址 (获得页框)由于 Page Directory 字段和 Page Table 段都是 10 位,因此其可寻址上限为 1024*1024 KB,Offset 可寻址的范围最大为 2^12(4096 字节)。因此,页目录的可寻址上限为 1024*1024*4096(等于 2^32 个内存单元,即 4 GB)。因此在 x86 架构上,总可寻址上限是 4 GB。
![]()
![]()
回页首
?
如您所知,在 64 位处理器中:
我们可以从架构中看到,实际上使用了 43 位进行寻址。因此在 64 位处理器中,可以有效使用的内存是 2 的 43 次方。
每个进程都有自己的页目录和页表。为了引用一个包含实际用户数据的页框,操作系统(在 x86 架构上)首先将 pgd 加载到?cr3?寄存器中。Linux 将?cr3?寄存器的内容存储到 TSS 段中。此后只要在 CPU 上执行新进程,就从 TSS 段中将另外一个值加载到?cr3?寄存器中。从而使分页单元引用一组正确的页表。
pgd 表中的每一条目都指向一个页框,其中中包含了一组 pmd 条目;pdm 表中的每个条目又指向一个页框,其中包含一组 pte 条目;pde 表中的每个条目再指向一个页框,其中包含的是用户数据。如果正在查找的页已转出,那么就会在 pte 表中存储一个交换条目,(在缺页的情况下)以定位将哪个页框重新加载到内存中。
图 8 说明我们连续为各级页表添加偏移量来映射对应的页框条目。我们通过进入作为分段单元输出的线性地址,再划分该地址来获得偏移量。要将线性地址划分成对应的每个页表元素,需要在内核中使用不同的宏。本文不详细介绍这些宏,下面我们通过图 8 来简单看一下线性地址的划分方式。
 ?
?![]()
![]()
回页首
?
当实现了对 Pentium II 的虚拟内存扩展的支持(在 32 位系统上使用 PAE ―― Physical Address Extension ―― 可以访问 64 GB 的内存)和对 4 GB 的物理内存(同样是在 32 位系统上)的支持时,高端内存区域就会出现在内核内存管理中了。这是在 x86 和 SPARC 平台上引用的一个概念。通常这 4 GB 的内存可以通过使用?kmap()?将?ZONE_HIGHMEM?映射到?ZONE_NORMAL?来进行访问。请注意在 32 位的架构上使用超过 16 GB 的内存是不明智的,即使启用了 PAE 也是如此。
(PAE 是 Intel 提供的内存地址扩展机制,它通过在宿主操作系统中使用 Address Windowing Extensions API 为应用程序提供支持,从而让处理器将可以用来寻址物理内存的位数从 32 位扩展为 36 位。)
这个物理内存区域的管理是通过一个?区域分配器(zone allocator)?实现的。它负责将内存划分为很多区域;它可以将每个区域作为一个分配单元使用。每个特定的分配请求都利用了一组区域,内核可以从这些位置按照从高到低的顺序来进行分配。
例如:
ZONE_NORMAL);如果失败,就从?ZONE_HIGHMEM?开始尝试;如果这也失败了,就从?ZONE_DMA?开始尝试。这种分配的区域列表依次包括?ZONE_NORMAL、ZONE_HIGHMEM?和?ZONE_DMA?区域。另一方面,对于 DMA 页的请求可能只能从 DMA 区域中得到满足,因此这种请求的区域列表就只包含 DMA 区域。
?
Vikram Shukla 具有 6 年使用面向对象语言进行开发和设计的经验,目前是位于印度 Banglore 的 IBM Java Technology Center 的一名资深软件工程师,负责对 IBM JVM on Linux 进行支持。