分库分表策略的可实现架构
?
分库分表是解决mysql水平扩展的主要手段。网上有关策略的讨论很多,主要是hash扩展、按时间扩展、按范围扩展等等。但真正想实施分库分表的朋友们往往觉得“策略听来终觉浅,觉知此事要代码”,因此本文的主要目的是给朋友们提供一个可实现架构。
JDBCTemplate和Hibernate大家都知道Hibernate是ORM(对象-关系数据库 mapping)意义上的第一个真正的“统治级”产品。JDBCTemplate则是对Spring对jdbc的简单封装,相对于Hibernate,工程师需要自己写sql,而不是像Hibernate那样直接操作对象解决数据库持久化的问题。因为暴露了sql,JDBCTemplate当然也不利于跨数据库(毕竟每个数据库的实现产品的sql也不竟相同)。但现在大多数互联网企业都倾向于使用JDBCTemplate,而不是Hibernate。个人认为主要原因就是性能问题,
?
1,为获取更好性能,往往根据不同数据库采用特有的优化方式,即使是DAO层全部用Hibernate实现,迁移数据库也不是轻松的工作。
2,使用Hibernate处理关联关系往往将大量数据信息加载到业务系统内存,而不是在数据库系统中处理,只是将最终结果返回。这样破坏了生产系统和DB的解耦,导致DB优化困难,以及生产系统的不安全。
3,分库分表对于Hibernate来说显得比较复杂
?
可以说第三个原因是主要的。本文会围绕JDBCTemplate来实现分库分表,如果你还在使用Hibernate,建议逐渐切换到JDCBTemplate。
?
分库分表策略分库分表策略,简单来说就是根据要被持久化的数据,分配一个库或者表来读/写。因此DBSplitStrategy接口定义如下,
?
interface DBSplitStrategy {String getDBName(long id); // 获取库名String getTableSuffix(long id); // 获取表名JdbcTemplate getIdxJdbcTemplate(long id); // 获取db jtJdbcTemplate getIdxJdbcTemplate(String dbname); // 根据库名获取 db jtJdbcTemplate getIdxJdbcTemplateByTable(String table); // 根据表名获取db jt}?接口定义是围绕最基本的:key -> 逻辑库名/表名 -> 物理库名/表名
?
实现类
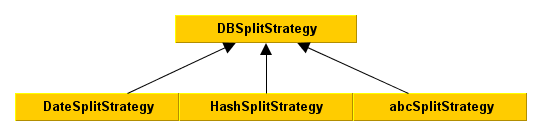
?以最常见的HashSplit为例,首先我们需要几个基本的配置项:(1)基本库名,也可以叫库名前缀;(2)分库总数;(3)分表总数;(4)分库对应的物理地址,即JDBCTemplate定义
有了以上配置,代码工作只需要把输入的关键词安装策略转换成逻辑库名、表名即可,伪代码如下,
?
public String getTableName(long id) { long hash = getHash4split(id, splitCount); return tbNameBase + String.valueOf(hash / shareDBCount + 1);}public String getDBName(long id) { long hash = getHash4split(id, splitCount); return dbNameBase + ( hash % shareDBCount + 1);}?这段代码里有个有趣的逻辑,如果你的业务主键从 1 一直增长,那么分库分表的结果就是:库1,表0;库2,表0;库3,表0;..... 库1,表2;库2,表2;...?
?
总结Mysql分库分表,水平扩展还有很多问题这里没有涉及到,比如,
?
?
?
本文纯属原创,欢迎引用,请注明本博地址:http://maoyidao.iteye.com/