【Lucene】构建索引
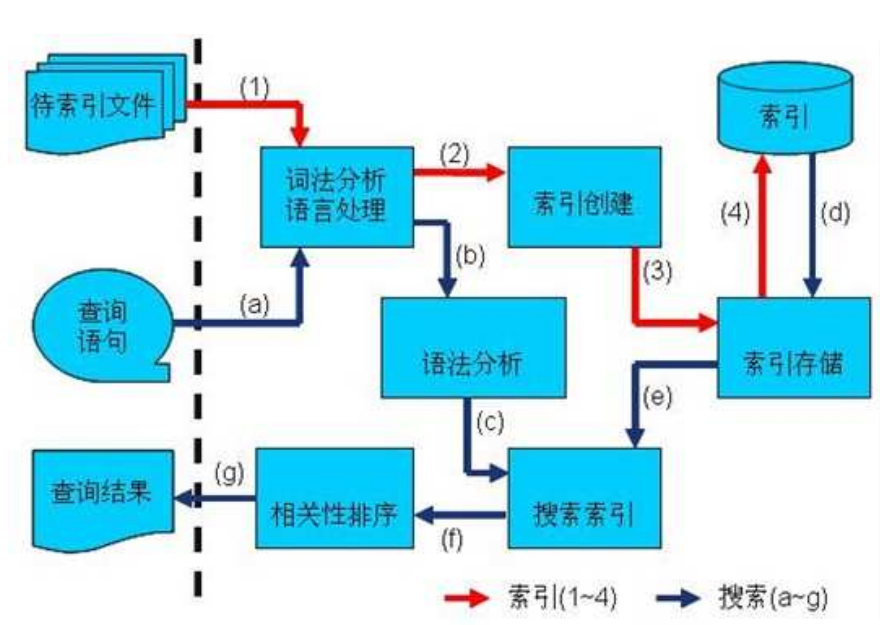
?Lucene索引的过程是什么?
step1 收集待索引的原文档
从数据库、web等获取原文档。
?
step2 将原文档交给分词组件(Tokenizer)
此过程叫做Tokenize,得到的结果称为Token。
?
会做如下几件事:
1.将文档分成一个个独立的单词
2.去除标点
3.去除停词(stopword)
?
step3 将得到的Token交给语言处理组件(Linguistic Processor)
此过程处理的结果是Term。
?
会做如下几件事:
1.转为小写
2.将单词缩减为词根,如cars-->car
3.将单词转变为词根,如drove-->drive
?
step4 将得到的Term交给索引组件(Indexer)
?
会做如下几件事:
1.将得到的Term创建字典
2.对字典按字母排序
3.合并相同的Term为倒排文档链表
?
倒排索引?
Normsnorms的范畴用于将加权因子写入索引。(关于文档和域加权操作见http://nemogu.iteye.com/admin/blogs/1452831)
搜索时,被搜索域的norms都被加载到内存中,用于relevance score。
?
?