搭建hadoop集群
一、前言
? ? ? 本文假设你对hadoop有理论上的了解,因此不对hadoop及其涉及的概念做基本介绍,仅记录如何搭建一个可用的hadoop集群。不过提到hadoop不得不提引导其出生的Google发表的MapReduce论文,顺便感慨下Google的强大。最近Google的风头逐渐被如日中天的Facebook盖过,再顺便感慨下互联网时代的风云变幻。
二、搭建
1、准备工作
? ? ? 要搭建一个物理上的hadoop集群,首先你得有几台机器吧,配置不用高,hadoop提倡的就是在低廉的物理设备上提供可靠的高性能计算能力。机器上装好Linux系统,JDK,ssh和hadoop。我用的是Ubuntu11.04,openjdk1.6和hadoop-0.19.1。另外配置好JAVA_HOME, HADOOP_HOME等环境变量,将HADOOP_HOME/bin加入PATH中。你可以去这里,根据上面的快速入门文档,在单机上跑一跑,看是否做好了全部准备工作。另外hadoop比较依赖JDK版本,0.19.x必须1.5以上版本,0.20.x则需1.6以上版本,如果你在配置集群或者运行MapReduce程序时出现莫名其妙的问题时需要检查你的JDK版本,可以去这里看看。
2、基础配置
? ? ? 首先确保你每台机器名不一样,改机器名修改这个文件/etc/hostname。通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker。这些机器是masters,可以是一台机器。余下的机器即作为DataNode也作为TaskTracker,这些机器是slaves。配置/etc/hosts文件指定master和slave的IP地址,我的配置如图所示:
? ? ? 进入hadoop根目录下的conf目录,修改masters和slaves文件,将我们的机器名添加进masters文件,slave机器名添加进slaves文件,注意一行一个。
? ? ? 修改conf目录下的hadoop-site.xml文件,下面是我在网上找到的一些配置信息,直接copy进去可用(注意里面目录信息记得根据自身机器情况进行修改):
<configuration>
<property>
?? <name>fs.default.name</name>
?? <value>hdfs://master:54310/</value>
</property>
<property>
?? <name>mapred.job.tracker</name>
?? <value>hdfs://master:54311/</value>
</property>
<property>
?? <name>dfs.replication</name>
?? <value>3</value> ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? #指定 HDFS 中每个 Block 被复制的次数,起数据冗余备份的作用。在典型的生产系统中,这个数常常设置为3
</property>
<property>
??? <name>hadoop.tmp.dir</name>
??? <value>/home/hadoop/tmp/</value> ? ? ?#hadoop的tmp目录路径
</property>
<property>
? <name>dfs.name.dir</name>
? <value>/home/hadoop/name/</value>????? #hadoop的name目录路径
</property>
<property>
?? <name>mapred.child.java.opts</name>
?? <value>-Xmx512m</value> ? ? ? ? ? ? ? ? ? ? ? ?#进程
</property>
<property>
? <name>dfs.block.size</name>
? <value>67108864</value>
</property> ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?#新文件默认block大小
<property>??
? <name>dfs.permissions</name>??
? <value>false</value> ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? #效验HDFS文件系统权限
</property>??
<property>??
?? <name>dfs.web.ugi</name>??
?? <value>hadoop,supergroup</value> ? ? ? ? ?#hadoop页面访问权限
</property>
<property>
?? <name>heartbeat.recheck.interval</name>
?? <value>5000</value> ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?#心跳间隔时间,5000秒=40分
</property>
</configuration>
这些都需要在每台机器里面配置,不同的是slaves中配置hadoop-site.xml文件时去掉
<property>
? <name>dfs.name.dir</name>
? <value>/home/hadoop/name/</value>?
</property>
改成:
<property>
? <name>dfs.data.dir</name>
? <value>/home/hadoop/data/</value>?
</property>
最后在hadoop根目录下建立临时文件目录tmp。
3、配置ssh
? ? ? 虽然hadoop框架本身不需要ssh,但是它的守护程序(比如TaskTracker,DataNode)需要用到,所以要配置ssh,保证命令执行时不需要再输入密码,根据前人 经验,如果都是Master启动和关闭hadoop的话只需要建立单向(master到slaves)ssh连接就可以了。配置的方法网上很多,前面的链接里面都有提到,这里就不再赘述了。
4、启动hadoop集群
? ? ? 启动Hadoop集群需要启动HDFS集群和Map/Reduce集群。启动之前需要格式化一个新的分布式文件系统,在master机器上运行:hadoop namenode –dfs。输入命令:start-dfs.sh启动HDFS,输入:start-mapred.sh启动MapReduce。也可以输入start-all.sh启动所有。
5、验证
? ? ? 输入命令:netstat –tnl可以看到hadoop的一些端口都已经开放了。在浏览器输入
http://master:50030
http://master:50070
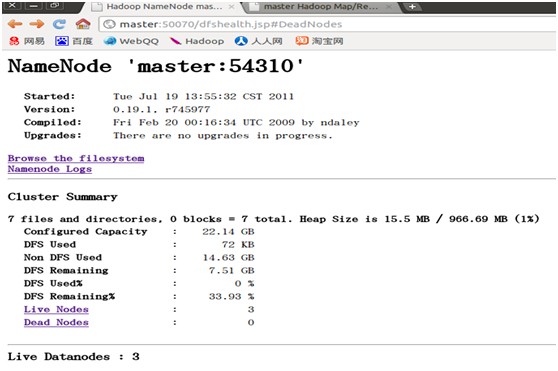
均可正常访问。在集群正常运行时可以访问这两个地址查看集群运行状况。
6、加入hadoop集群
? ? ? 如果一个hadoop集群已经在运行中,你又有了一些slave机器或者是宕掉的机器想加入这个集群,前者需要在master机器的HADOOP_HOME/conf/slaves文件中添加自己的机器名,再执行:
? ? ? hadoop-daemon.sh start datanode
? ? ? hadoop-daemon.sh start tasktracker
即可不用停掉集群动态添加进去。
7、停止hadoop集群
? ? ? stop-dfs.sh停用HDFS, stop-mapred.sh停用MapReduce。或者输入stop-all.sh。
三、总结
? ? ? 集群的搭建工作并不是一件太难的事情,关键在于深入了解hadoop的内部运行机制,根据不同的情况对集群做一些优化配置,特殊的情况需要对hadoop源码进行一些改进。集群的配置还需要根据长期的生产运行跟进监控,不断的改进使它更适合我们的生产环境,没有最好的配置,只有最适合我们的配置。
?
1 楼 zhanzhan02 2011-07-19 犀利啊 顶 希望可以连载