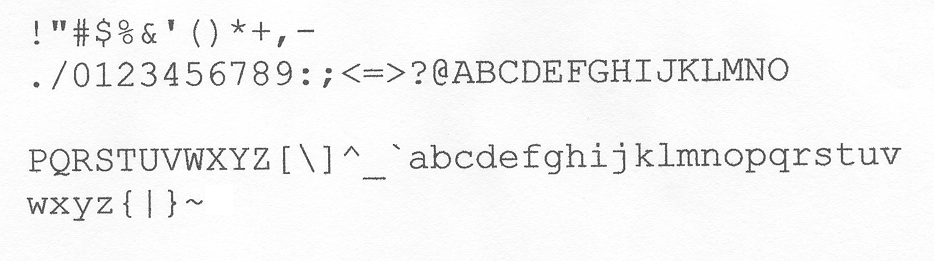识别验证码,你有几分成功率?
? 现在验证码几乎在任何一个网站的交互界面中都存在,目的当然是为了防止恶意程序的攻击。如果我们想获取到验证码,就需要从这个验证码的图片中分析出来到底是什么字符。这就需要 OCR 技术。
?
100% ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 从上面的图表我们看出, 针对干扰过的验证码, 三个软件都没能识别出来,而针对比较简单的规则数字组成的验证码, 三个软件的识别率都高达 100%。 我们细分析下两组验证码之间的不同: ? ? 在第一组验证码中: 每个字符都有倾斜,而且倾斜角度不同 每个字符的大小有稍微的不同 字符中间没有空隙 有另外一道干扰的黑线不规则的穿过其中的几个字符 每个字符的字体稍微不同 ? ? 在第二组验证码中: 字符间有很大的空隙 字符都加粗 字体大小统一 字体一样 ? 从实验结果上看,如果想提高识别率的话, 图片应尽量向第二组的图片靠拢。 那为什么第二组的图片识别率高呢?我们看下 OCR 的原理。 ? OCR 原理 ? OCR 在扫描目标图片的时候, 需要加载 Trained Image,分割目标图片中的文字到单个字符[1],然后遍历每个 Trained Image 里的字符图片, 从而推测出图片里字符是什么。 ? 加载 Trained Image ? OCR 程序之所以能够识别出图片中的字符,是要有个图片库进行比对的, 这个图片库一般被称为 Trained Image, 一般都允许用户自己定义新的 Trained Image。每个 Trained Image 里都有很多字符, 基本都是按照行列分布, 格式一般为 PCX 格式。每个 Trained Imge 都有自己的元数据, 说明哪个区间里的图片对应哪个字符。 程序加载 Trained Image 的时候, 会先分析有多少行,然后逐行扫描,再分析有多少列, 然后精确到一个区间坐标: [(x1, y1), (x,y2)], 其中 x 为 行, y 为列。然后根据元数据把该区间对应的字符和区间里的图片对应起来。研究了下 Java OCR 加载 Trained Image 的时候, 是通过分析一行里所有的像素点的值是否有都大于一个浅色值 128 来判定当前行是行间隙还是行中间,同理适用于列扫描。 下面这张图片是个典型的 Trained Image: ? ?? 扫描目标图片 ? 加载 Trained Image 后, OCR 程序会根据同样的原理分割目标图片中的文字到单个字符[2], 然后逐个比对 Trained Image 里的字符图片, 找到最匹配的字符。 一般匹配的时候,会比较图片的长宽比率差是否在容忍范围内; 上下左右四个方向的空白区域宽度差是否在容忍范围内;目标图片的大小是否和 Trained Image 相差太大等等。 ? ? 从原理上看,识别的准确度在于三点: 那怎样提高识别率呢? 针对以上三点: ? ? 当前国内大多网站的验证码都已经过千锤百炼, 验证码几乎连人都看不清了, 何况程序乎? 所以我认为如果网站想真正发挥验证码的作用,程序是识别不出来的。像第二组那样的验证码,不知道有什么存在价值(第二组的验证码这个来自一个国企的邮箱登录界面)。 ? ? [1] 也可能有分割到词的,这里只表述我研究的 Java OCR 。 [2] 分割目标图片的时候,有可能不仅仅需要靠间隙,应该还有其他方法, 这里只列举 Java OCR 使用的。![]()
![]()
![]()
![]()
![]() 准确率Tesseract OCR ZYQQDSGWHRKSGWWPT0%Asprise OCR-----0%Java OCR-----0%0.jpg
准确率Tesseract OCR ZYQQDSGWHRKSGWWPT0%Asprise OCR-----0%Java OCR-----0%0.jpg![]()
![]()
![]()
![]()
![]() 准确率
准确率
Tesseract OCR32840985779114118986100%Asprise OCR32840985779114118986100%Java OCR32840985779114118986