ThreadPoolExecutor几点使用建议
前段时间一个项目中因为涉及大量的线程开发,把jdk cocurrent的代码重新再过了一遍。这篇文章中主要是记录一下学习ThreadPoolExecutor过程中容易被人忽略的点,Doug Lea的整个类设计还是非常nice的
?
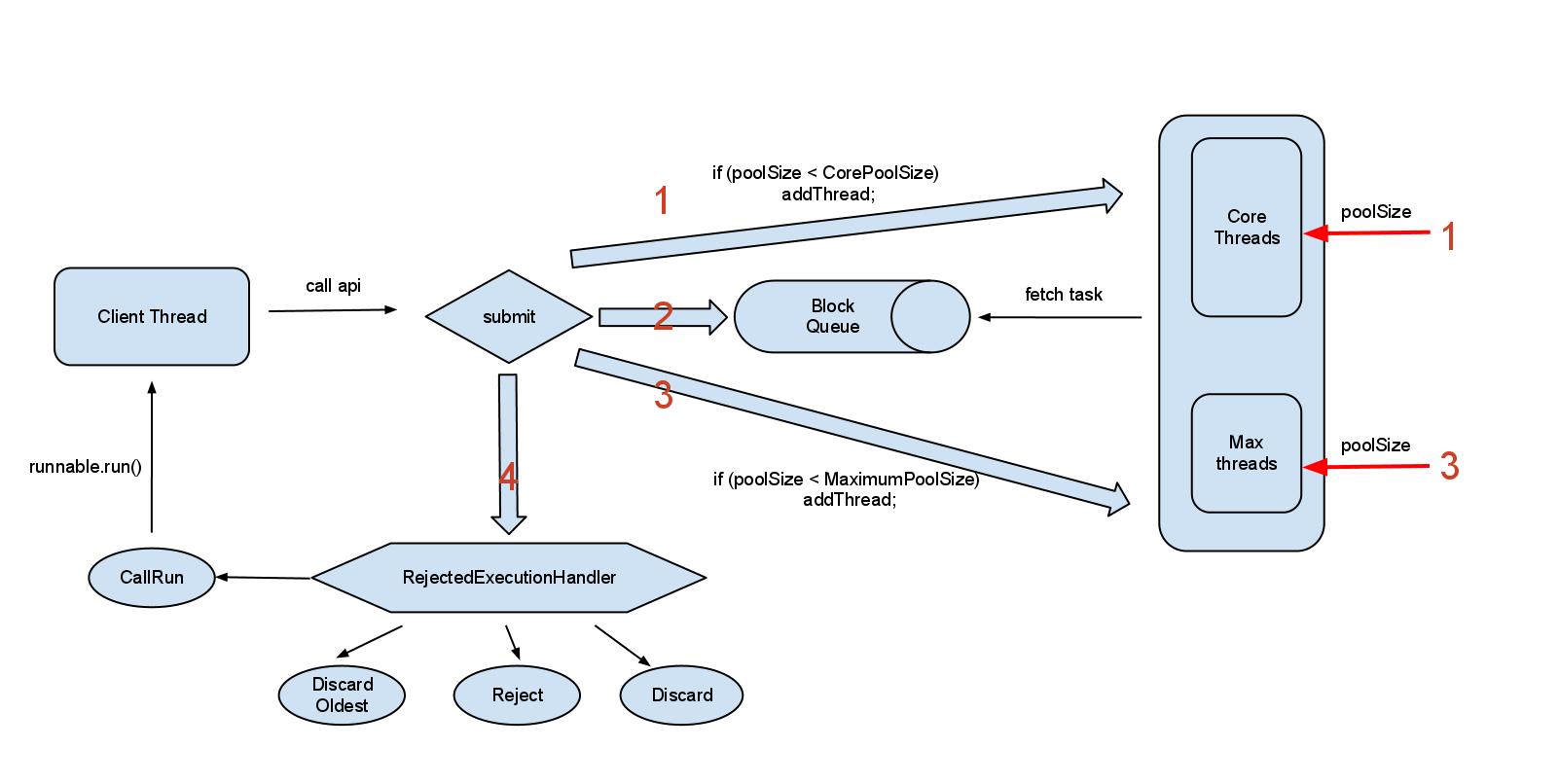
先看一副图,描述了ThreadPoolExecutor的工作机制:?
?
整个ThreadPoolExecutor的任务处理有4步操作:
?
第一步,初始的poolSize < corePoolSize,提交的runnable任务,会直接做为new一个Thread的参数,立马执行第二步,当提交的任务数超过了corePoolSize,就进入了第二步操作。会将当前的runable提交到一个block queue中再提供一个btrace脚本,分析线上的thread pool容量规划是否合理,可以运行时输出poolSize等一些数据。
?
?
import static com.sun.btrace.BTraceUtils.addToAggregation;import static com.sun.btrace.BTraceUtils.field;import static com.sun.btrace.BTraceUtils.get;import static com.sun.btrace.BTraceUtils.newAggregation;import static com.sun.btrace.BTraceUtils.newAggregationKey;import static com.sun.btrace.BTraceUtils.printAggregation;import static com.sun.btrace.BTraceUtils.println;import static com.sun.btrace.BTraceUtils.str;import static com.sun.btrace.BTraceUtils.strcat;import java.lang.reflect.Field;import java.util.concurrent.atomic.AtomicInteger;import com.sun.btrace.BTraceUtils;import com.sun.btrace.aggregation.Aggregation;import com.sun.btrace.aggregation.AggregationFunction;import com.sun.btrace.aggregation.AggregationKey;import com.sun.btrace.annotations.BTrace;import com.sun.btrace.annotations.Kind;import com.sun.btrace.annotations.Location;import com.sun.btrace.annotations.OnEvent;import com.sun.btrace.annotations.OnMethod;import com.sun.btrace.annotations.OnTimer;import com.sun.btrace.annotations.Self;/** * 并行加载监控 * * @author jianghang 2011-4-7 下午10:59:53 */@BTracepublic class AsyncLoadTracer { private static AtomicInteger rejecctCount = BTraceUtils.newAtomicInteger(0); private static Aggregation histogram = newAggregation(AggregationFunction.QUANTIZE); private static Aggregation average = newAggregation(AggregationFunction.AVERAGE); private static Aggregation max = newAggregation(AggregationFunction.MAXIMUM); private static Aggregation min = newAggregation(AggregationFunction.MINIMUM); private static Aggregation sum = newAggregation(AggregationFunction.SUM); private static Aggregation count = newAggregation(AggregationFunction.COUNT); @OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "execute", location = @Location(value = Kind.ENTRY)) public static void executeMonitor(@Self Object self) { Field poolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "poolSize"); Field largestPoolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "largestPoolSize"); Field workQueueField = field("java.util.concurrent.ThreadPoolExecutor", "workQueue"); Field countField = field("java.util.concurrent.ArrayBlockingQueue", "count"); int poolSize = (Integer) get(poolSizeField, self); int largestPoolSize = (Integer) get(largestPoolSizeField, self); int queueSize = (Integer) get(countField, get(workQueueField, self)); println(strcat(strcat(strcat(strcat(strcat("poolSize : ", str(poolSize)), " largestPoolSize : "), str(largestPoolSize)), " queueSize : "), str(queueSize))); } @OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "reject", location = @Location(value = Kind.ENTRY)) public static void rejectMonitor(@Self Object self) { String name = str(self); if (BTraceUtils.startsWith(name, "com.alibaba.pivot.common.asyncload.impl.pool.AsyncLoadThreadPool")) { BTraceUtils.incrementAndGet(rejecctCount); } } @OnTimer(1000) public static void rejectPrintln() { int reject = BTraceUtils.getAndSet(rejecctCount, 0); println(strcat("reject count in 1000 msec: ", str(reject))); AggregationKey key = newAggregationKey("rejectCount"); addToAggregation(histogram, key, reject); addToAggregation(average, key, reject); addToAggregation(max, key, reject); addToAggregation(min, key, reject); addToAggregation(sum, key, reject); addToAggregation(count, key, reject); } @OnEvent public static void onEvent() { BTraceUtils.truncateAggregation(histogram, 10); println("---------------------------------------------"); printAggregation("Count", count); printAggregation("Min", min); printAggregation("Max", max); printAggregation("Average", average); printAggregation("Sum", sum); printAggregation("Histogram", histogram); println("---------------------------------------------"); }}?运行结果:
?
poolSize : 1 , largestPoolSize = 10 , queueSize = 10reject count in 1000 msec: 0
?
说明:
1. poolSize 代表为当前的线程数
2. largestPoolSize 代表为历史最大的线程数
3. queueSize 代表blockqueue的当前堆积的size
4. reject count 代表在1000ms内的被reject的数量
?
?
??这是我对ThreadPoolExecutor使用过程中的一些经验总结,希望能对大家有所帮助,如有描述不对的地方欢迎拍砖。
?