nutch 搜索site dedup
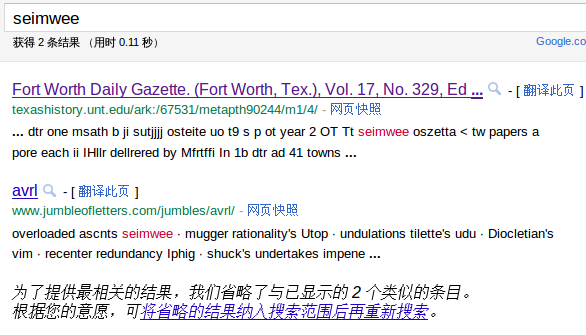
这个版本发现有个大大的bug,就是搜索时同一页面出现重复,不同页面也出现重复。即使有check dedup功能,也不起作用。
后来把代码修改一个才行,被搞晕。。。
?
?
其实关键代码就在于NutchBean.search(query)中。以下来分析一下。
?
?
一。概念
hitsPerPage:相当count of a page
hitsPerSite:that is how many elements in a site per whole searches by same keyword
totalIsExact:如果没有site dup,那么就是true
numHits:就是期望的topn
seen:dedulicated set
?
二。流程
首先外部有个大循环,根据length()进行;内?一个loop,表明如果是有dup site便进行扩展搜索。
?
其实
其实这里的功能相当上图中的最后一行功能。
??
这就是similarity功能了,与site相当,只是在最后显示而已。
?
?
??
无意中发现bing的搜索有这样的結果:每页只有一个url。。。
?
?
?
?
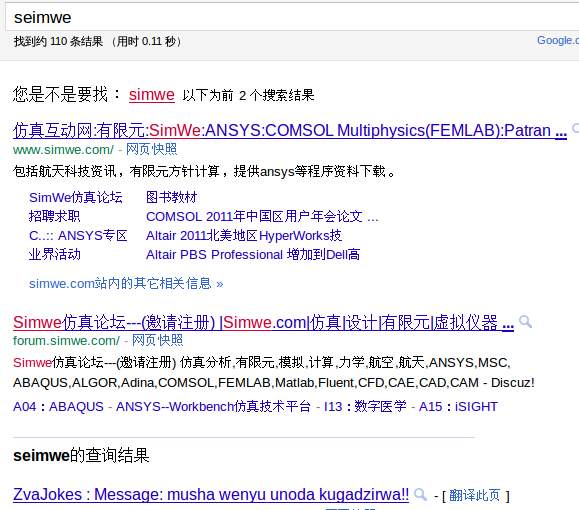
其实这个site功能的搜索总数是不固定的,就像上图一样,每次搜索結果都不一样,所以gg也是不同的页数显示数量不一样。但在nutch中,是故意将total先保存下来,最后和reset,就显得总数保持不变,其实这样做是不对的。应该向gg学习!
?
?
?
?